

VI. Le modèle de programmation▲
Pour un développeur CUDA, l'ordinateur consiste en un ou plusieurs hôtes, un traditionnel CPU et un ou plusieurs périphériques, des non moins traditionnels GPU, des processeurs massivement parallèles.
Dans les applications modernes, certaines parties utilisent du calcul qui peut facilement devenir parallèle, sans aucun problème. Ces parties peuvent être déportées de l'hôte vers le périphérique.
VI-A. Parallélisme des données▲
Les applications actuelles qui doivent traiter de grandes quantités de données prennent beaucoup de temps à l'exécution. Ce temps pourrait être réduit en parallélisant les opérations : des phénomènes physiques peuvent être calculés indépendamment les uns des autres, des images à analyser peuvent être découpées en portions et un flux vidéo peut être découpé image par image.
La parallélisation des données réfère à la propriété du programme de gérer parallèlement et indépendamment ces instructions arithmétiques.
Par exemple, pour des multiplications de matrices de taille 1000 x 1000, il s'agit de 1 000 000 de multiplications, sans rapport les unes avec les autres, qui peuvent donc être parallélisées sans problème. Un GPU peut fortement améliorer les performances en exécutant toutes ces opérations simultanément.
VI-B. Structure du programme▲
Un programme CUDA est constitué d'une partie qui s'exécute sur l'hôte et d'une partie qui s'exécute sur le périphérique.
Les phases peu ou pas parallèles sont exécutées sur l'hôte.
Les phases massivement parallèles sont exécutées sur le périphérique.
Le programme peut tenir en un seul fichier, comprenant ces deux phases et environnements. Le compilateur se charge de les séparer : le code pour l'hôte est du standard C ANSI/ISO et est compilé par le compilateur principal du système, il sera lancé comme un simple processus. Le code pour le périphérique est aussi écrit en C ANSI/ISO, avec quelques extensions CUDA, mais il est compilé par NVCC et sera exécuté sur le périphérique.
Les kernels génèrent généralement beaucoup de threads pour exploiter au mieux le parallélisme des données.
Dans notre exemple de produit matriciel, il y a autant de threads que de cellules dans la matrice résultante. Chacun de ces threads prend, généralement, très peu de cycles, vu le peu de tâches qui leur sont demandées.
L'exécution commence avec le CPU, qui prépare l'appel au kernel. Le GPU prend le relais pour le kernel, qui sera, lui, massivement multithread. Quand le kernel a fini sa tâche, il renvoie le résultat au CPU et son exécution continue.
VI-C. L'exemple : la multiplication de matrices carrées▲
Pour commencer par clarifier la situation, voici le fonctionnement que décrira notre programme :
- CPU : initialisation des matrices M, N et P, toutes carrées ;
- CPU : remplissage des matrices d'entrée M et N ;
- GPU : calcul du produit matriciel de M et de N, dont le résultat est stocké sur P ;
- CPU : écriture de la matrice P ;
- CPU : nettoyage de la mémoire et fin de l'exécution du programme.
Nous avons vu les différents types de mémoire, mais pas la manière d'y accéder. Or, cela sera nécessaire pour permettre l'exécution du programme. Nous allons ici nous concentrer sur l'utilisation de la mémoire globale, le but étant de montrer le fonctionnement d'un programme CUDA et non d'optimiser au maximum une application.
Ces fonctions se trouvent, heureusement, dans l'API CUDA. Leur nom est très recherché : cudaMalloc() et cudaFree().
Voici un bref exemple d'utilisation de ces deux fonctions, très proches des fonctions malloc() et free() du C. On considère que Width est le nombre de lignes et de colonnes de la matrice pour laquelle on crée l'espace mémoire.
float *Md;
float *Nd;
float *Pd;
const int size = Width * Width * sizeof(float);
cudaMalloc( (void**) & Md, size);
cudaMalloc( (void**) & Nd, size);
cudaMalloc( (void**) & Pd, size);
cudaFree ( Md );
cudaFree ( Nd );
cudaFree ( Pd );cudaMalloc() prend deux paramètres, pour définir la mémoire à allouer en mémoire globale :
- L'adresse d'un pointeur vers la mémoire allouée ;
- La taille de la mémoire à allouer.
cudaFree() ne prend qu'un paramètre, pour désallouer cette mémoire en mémoire globale:
- Un pointeur vers la mémoire à désallouer.
Une fois que le programme a alloué sa mémoire, il peut demander les données des matrices à stocker en mémoire.
Ceci s'obtient avec une fonction de copie de mémoire : cudaMemcpy(). Cette fonction requiert quatre paramètres :
- Un pointeur vers les données source à copier ;
- La destination des données ;
- Le nombre d'octets à copier ;
- Le type de mémoire vers laquelle copier.
Concernant le quatrième paramètre, il peut prendre une de ces valeurs :
- cudaMemcpyHostToDevice : copie de l'hôte vers le périphérique ;
- cudaMemcpyHostToHost : copie de l'hôte vers l'hôte ;
- cudaMemcpyDeviceToHost : copie du périphérique vers l'hôte ;
- cudaMemcpyDeviceToDevice : copie du périphérique vers le périphérique.
Voici les appels réalisés pour copier les matrices sur lesquelles nous allons travailler et pour envoyer le résultat à l'endroit souhaité. M, N, P, Md, Nd, Pd et size gardent leur valeur précédente.
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice);
cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);
cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);Tous ces transferts de mémoire sont asynchrones !
Maintenant que nous savons ce que nous pouvons faire avec la mémoire et comment le faire, nous pouvons commencer l'implémentation de notre exemple. Normalement, à ce stade de votre étude de CUDA, vous devriez pouvoir écrire correctement ce kernel (ce qui est fortement recommandé, il s'agit d'un exercice comme un autre), et voici la correction.
__global__ void MatrixMulKernel(float * Md, float * Nd, float * Pd, int Width)
{
// identifiant de thread à deux dimensions, comme la matrice
int tx = threadIdx.x;
int ty = threadIdx.y;
// Pvaleur sert au stockage de la valeur calculée par le thread
float Pvaleur = 0;
for (int i = 0; i < Width; ++i)
{
float MdElement = Md[ty * Width + i];
float NdElement = Nd[i * Width + tx];
Pvaleur += MdElement * NdElement;
}
// écrit la valeur calculée dans la matrice de résultat
// chaque thread ne peut écrire qu'une valeur !
Pd[ty * Width + tx] = Pvaleur;
}Et voici l'utilisation de ce kernel, que vous devriez aussi pouvoir écrire.
void MatrixMulOnDevice(float * M, float * N, float * P, int Width)
{
//calcul de la taille des matrices
int size = Width * Width * sizeof(float);
//allocation des matrices et leur remplissage
cudaMalloc(Md, size);
cudaMemcpy(Md, M, size, cudaMemcpyHostToDevice) ;
cudaMalloc(Nd, size);
cudaMemcpy(Nd, N, size, cudaMemcpyHostToDevice);
//allocation de la matrice de résultat
cudaMalloc(Pd, size);
//multiplication d'une seule matrice
dim3 dimGrid(1, 1);
//matrice carrée
dim3 dimBlock(Width, Width);
//produit matriciel proprement dit
MatrixMulKernel<<<dimGrid, dimBlock>>>(Md, Nd, Pd, Width);
//récupération du résultat du calcul
cudaMemcpy(P, Pd, size, cudaMemcpyDeviceToHost);
//destruction des matrices, désormais inutilisées
cudaFree(Md);
cudaFree(Nd);
cudaFree(Pd);
}Pour que ce code compile, vous devez inclure les fichiers cuda.h et cuda_runtime.h.
VI-D. Séparer les opérations à effectuer▲
Comme souvent dit plus haut, le périphérique exécute beaucoup de calculs en même temps. Il est donc bien nécessaire de découper ses calculs en autant de petits morceaux, algorithmiquement identiques.
Prenons un exemple : le traitement de données sismiques. Il s'agit d'analyser une image, à trois dimensions, pixel par pixel, pour vérifier l'évolution de la situation. Nous allons nous concentrer sur l'imagerie de Kirchhoff.
Dans ce cas, une grille représente une image à analyser, avec deux dimensions, qui correspondent aux largeur et hauteur de l'image. Un bloc aura donc l'abscisse et l'ordonnée déjà fixées, la seule dimension à encore faire varier est la cote : voici donc le nombre de threads par bloc. Chaque thread aura donc ses trois coordonnées définies par ses places dans la grille et dans le bloc, il comparera ce pixel avec celui de l'image précédente.
Ceci correspond, plus ou moins, à l'algorithme utilisé sur un CPU : il est constitué de trois boucles imbriquées, chacune faisant varier une coordonnée. Basiquement, ces boucles ne sont pas parallélisées, mais cela peut être effectué sans problème, ce qui améliore sensiblement les performances.
VII. Conclusions▲
Nous avons fini une très brève introduction aux possibilités offertes par CUDA. Nous n'avons vu que le strict nécessaire pour commencer à écrire des programmes CUDA et les compiler.
Vous avez pu vous rendre compte de la simplicité d'écrire du code avec CUDA. Cette approche, relativement haut niveau, ne permet pas au premier abord une optimisation approfondie. Pour ce genre d'exercice, il faut se tourner vers une solution plus proche du matériel, comme l'antique CTM. Cependant, optimiser à ce niveau augmente considérablement le temps de développement (si vous avez déjà utilisé l'assembleur, vous savez ce que c'est).
VII-A. Et chez AMD/ATI ?▲
Cette société a été la première à dégainer avec CTM, mais elle a pris du retard : son langage haut-niveau a été lancé en 2008, soit deux ans après CUDA. Donc, le langage Brook a été repris. Mais il produisait du code OpenGL. AMD l'a donc amélioré pour qu'il produise du CAL (proche de l'assembleur). Et s'est arrêté là.
Dernièrement, ils ont abandonné Brook+ (leur version de Brook) pour OpenCL, qui est en passe de devenir un standard accepté par tous (y compris NVIDIA, dont le support est disponible en bêta privée pour le moment).
Il n'est pas possible d'utiliser le GPU comme processeur sans le remarquer à toutes les lignes : il faut commencer par une initialisation, qui doit préciser la version des Shaders à utiliser. Certaines commandes existent en version DirectX9 et DirectX10.
La documentation n'est pas là pour aider : aussi brouillonne que l'interface, elle est plus qu'illisible. Principal grief : l'emploi des noms pour les GPU. Nous entendons parler de Radeon HD 2900, de R600, de Pele. Qui ne sont, en fait, que les mêmes GPU…
De quoi rebuter facilement du monde. Même si l'architecture peut être plus performante et permet une double précision (FP64) depuis plus longtemps.
Dernier point : le SDK pour AMD Stream est réservé à ses GPU, réservés aux professionnels. La firme se détourne complètement des GPU grand public, contrairement à son opposant.
VII-B. Intégration à Visual Studio▲
CUDA est prévu pour le compilateur de Visual Studio, sous Windows, alors que NVIDIA ne propose strictement aucun moyen d'intégrer le SDK dans l'IDE. C'est pourquoi Kaiyong Zhao a créé un modèle de projet pour cet IDE. Ce modèle est compatible avec Visual Studio 2005 (8.0) et 2008 (9.0).
Il vous suffit d'aller sur le site web du projet pour télécharger le modèle, puis de l'installer. Ainsi, un nouveau type de projet sera disponible à la création.
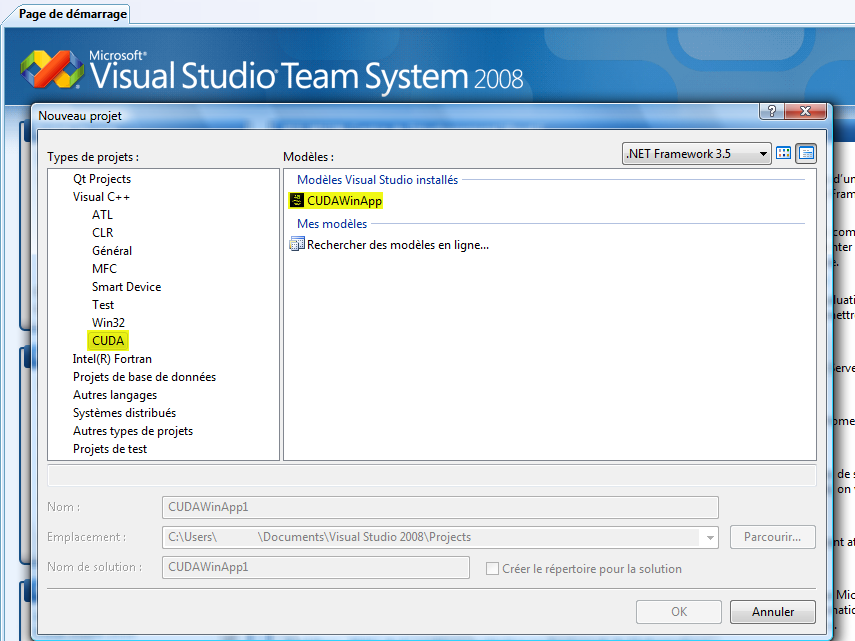
Cependant, cela ne vous apportera pas la coloration syntaxique du code. Pour ce faire, ouvrez le fichier C:\Program Files\Microsoft Visual Studio 9.0\Common7\IDE\usertype.dat (chemin à modifier selon votre installation). S'il n'existe pas, créez-le. Ajoutez-y le contenu de C:\Program Files\NVIDIA Corporation\NVIDIA CUDA SDK\doc\ syntax_highlighting\visual_studio_8\usertype.dat. Il s'agit de l'ensemble des mots-clés, des types, des variables prédéfinies et des fonctions mathématiques de base de CUDA. Ce fichier convient aux versions 7.0, 7.1, 8.0 et 9.0.
Maintenant, il faut que Visual Studio utilise une coloration syntaxique, semblable à celle du C et du C + +, avec les quelques mots-clés que nous venons d'ajouter, pour les fichiers CUDA.
Pour les versions 7.0 et 7.1, utilisez le fichier C:\Program Files\NVIDIA Corporation\NVIDIA CUDA SDK\doc\ syntax_highlighting\visual_studio_7\install_cuda_highlighting_vs7.reg.
Pour les autres versions, Outils > Options > Éditeur de texte > Extension de fichier, ajoutez les extensions cu et cuh, avec l'éditeur Visual C + +.
Et voilà ! Visual Studio est maintenant fin prêt à créer de nouveaux projets CUDA et à les mettre en couleur comme il le faut !
Il existe une autre solution : le fichier de règles pour CUDA. Il s'utilise comme tous les autres fichiers de règles. Placez ce fichier dans le dossier Microsoft Visual Studio 9.0\VC\VCProjectDefaults\ : cuda.rules. De cette manière, tous les projets disposeront des règles pour construire des fichiers .cu.
VII-C. Avec d'autres environnements de compilation▲
CUDA étant compatible avec une pléthore de compilateurs, pourquoi serait-il impossible de l'utiliser avec d'autres chaînes de compilation ? Ici ne sera montré qu'un bref exemple avec qmake.
qmake est la chaîne de compilation utilisée avec la bibliothèque C + + Qt, éditée par Nokia. Voici un petit script qui vous permettra d'utiliser le framework Qt et la bibliothèque C for CUDA sans problème de génération du côté Qt. Il vous suffit d'ajouter à la variable CUDA_SOURCES les fichiers qui doivent passer par nvcc.
win32 {
INCLUDEPATH += $(CUDA_INC_DIR)
QMAKE_LIBDIR += $(CUDA_LIB_DIR)
LIBS += -lcudart
cuda.output = $$OBJECTS_DIR/${QMAKE_FILE_BASE}_cuda.obj
cuda.commands = $(CUDA_BIN_DIR)/nvcc.exe -c -Xcompiler $$join(QMAKE_CXXFLAGS,",") $$join(INCLUDEPATH,'" -I "','-I "','"')
cuda.commands += ${QMAKE_FILE_NAME} -o ${QMAKE_FILE_OUT}
}
unix {
# auto-detect CUDA path
CUDA_DIR = $$system(which nvcc | sed 's,/bin/nvcc$,,')
INCLUDEPATH += $$CUDA_DIR/include
QMAKE_LIBDIR += $$CUDA_DIR/lib
LIBS += -lcudart
cuda.output = ${OBJECTS_DIR}${QMAKE_FILE_BASE}_cuda.obj
cuda.commands = nvcc -c -Xcompiler $$join(QMAKE_CXXFLAGS,",") $$join(INCLUDEPATH,'" -I "','-I "','"')
cuda.commands += ${QMAKE_FILE_NAME} -o ${QMAKE_FILE_OUT}
cuda.depends = nvcc -M -Xcompiler $$join(QMAKE_CXXFLAGS,",") $$join(INCLUDEPATH,'" -I "','-I "','"')
cuda.depends += ${QMAKE_FILE_NAME} | sed "s,^.*: ,," | sed "s,^ *,," | tr -d '\\\n'
}
cuda.input = CUDA_SOURCES
QMAKE_EXTRA_UNIX_COMPILERS += cudaVII-D. Déploiement▲
Vous ne devrez déployer strictement aucune DLL ou autre à côté de votre application : CUDA est intégré aux pilotes graphiques, depuis CUDA 1.1 et les pilotes de génération 177 pour GeForce. Par contre, pour que votre application fonctionne, il faut que le client dispose d'une carte graphique compatible et de pilotes supportant CUDA ; ou alors que vous compiliez votre application en mode émulation.
Cependant, ceci n'est valable que si vous n'utilisez que le driver de CUDA. Si vous utilisez le runtime (présenté ici), vous devrez aussi en distribuer la DLL (cudart.dll).
Si le client ne dispose pas d'une carte graphique compatible, vous ne devrez pas livrer de DLL particulière si vous vous limitez à CUDA : si vous utilisez une autre bibliothèque, vous devrez aussi en livrer la DLL d'émulation (suffixée par _emu).
VII-E. Quels fichiers inclure ?▲
Ici, je n'ai parlé que du runtime : il est composé de deux fichiers, cuda_runtime.h et cuda_runtime_api.h. Tous deux sont nécessaires pour pouvoir utiliser l'ensemble des fonctionnalités du runtime.
VIII. Divers▲
VIII-A. Références▲
- ECE Illinois - cours 498 AL : Programming Massively Parallel ProcessorsProgramming Massively Parallel Processors
- Tesla 10 & Cuda 2.0
- CUDA, Supercomputing for the Masses
- The End of the CPU ?
- GPU Workshop
- CUDA Textbook, disponible sur le site du MIT
- NVIDIA CUDA Programming Guide (versions 2.1 et 2.2), distribué avec le SDK
- NVIDIA NVCC Guide (versions 2.1 et 2.2), distribué avec le SDK
VIII-B. Voir aussi▲
VIII-C. Remerciements▲
Un tout grand merci à raptor70, à gorgonite, à ange_blond, à TanEk et surtout à IrmatDen, Matthieu Brucher, et à 3DArchi pour sa courageuse relecture, et Étienne Bougoin, ainsi que Sébastien Flochlay, pour leurs commentaires, encouragements et précisions, sans lesquels l'article ne serait pas celui qu'il est maintenant !
Merci aussi à tous les lecteurs qui ont relevé les quelques fautes qui se trouvaient encore dans l'article : L0ur5.