





I. Approche orientée objet▲
I-A. Introduction▲
L'approche orientée objet a pour objectif de faciliter la création de programmes modulaires en en facilitant l'écriture et la maintenance. L'environnement Java en est une implémentation parmi d'autres ; parmi ses avantages, on peut compter une grande communauté d'utilisateurs.
L'objectif de cette approche est de faciliter la production de programmes possédant de bonnes qualités de modularité : on veut développer une partie d'un programme sans qu'il soit nécessaire de connaître les détails d'implémentation des autres parties (on pourra modifier un module sans que cela n'affecte le reste du programme) tout en favorisant la réutilisabilité.
Pour ce faire, on se basera sur des objets, des structures de données présentes en mémoire, combinant données et code. Ce code détermine ce que l'objet peut effectuer. Un objet possédera une interface (publique ; cela inclut toutes ses méthodes publiques) et une implémentation (cachée ; cela inclut les variables et le corps des méthodes). L'exécution d'un programme sera vue comme l'échange de messages entre ces objets.
Une classe spécifie les caractéristiques des objets qu'elle aide à instancier. Tout objet est une instance d'une classe.
Un objet qui reçoit un message en accepte la responsabilité et effectuera l'opération ainsi demandée. À cet effet, il peut déléguer tout ou partie de cette responsabilité à d'autres objets.
I-A-1. Prérequis▲
On attend du lecteur une certaine expérience de la programmation (de préférence en langage C ou ayant une syntaxe similaire, étant donné que les structures de contrôle autres fonctionnalités de base de tout langage procédural ne seront pas réexpliquées dans la partie Java).
I-B. Classes et méthodes▲
Une classe peut être vue comme un type de données abstrait (TDA) : elle regroupe une interface (les opérations autorisées pour ses instances) et une implémentation (variables internes et corps des méthodes). Selon le principe de l'encapsulation, seule l'interface est accessible depuis l'environnement.
I-B-1. Principe de Parnas▲
Le principe de Parnas explique qu'il ne faut pas fournir trop d'informations à l'utilisateur d'une classe : la définition d'une classe fournit à l'extérieur toutes les informations nécessaires à la manipulation de ses instances et rien d'autre. De même, l'implémentation de ses méthodes se base sur toutes les informations nécessaires à la tâche et rien d'autre.
Notamment, on ne peut pas documenter l'implémentation d'une classe ou se baser sur des hypothèses qui ne seront pas vraies dans chaque cas d'utilisation possible.
I-B-2. Visibilité▲
Plusieurs visibilités sont possibles : public ou privé, notamment (on distinguera également protégé avec l'héritage et package ou défaut en Java). En UML, on les distingue par + et - (# pour la visibilité protégée, ~ pour la visibilité par défaut en Java).
Un élément public est accessible par tout objet.
Un élément privé d'un objet n'est accessible que par les instances de la classe à laquelle il appartient (notamment, toutes les variables, sauf rare exception : un objet extérieur ne peut pas modifier l'état de l'objet courant, sous peine de le mettre dans un état incohérent et de dépendre de ses structures internes, ce qui conduirait à des programmes peu fiables et peu modulaires).
Un élément protégé n'est visible qu'à la classe courante et aux classes filles
I-B-3. Variables▲
On distingue les variables de classe (dont une seule instance est partagée entre tous les objets d'une même classe) et les variables d'instance (qui existent pour chaque objet).
En UML, on souligne les éléments de classe.
Par exemple, pour émettre une série de tickets de caisse, il vaut mieux utiliser une variable de classe : on veut que chaque nouveau ticket ait le numéro immédiatement suivant le précédent et que chaque numéro soit unique. On stockera donc comme variable de classe le numéro courant ; à l'initialisation d'un nouveau ticket, on incrémentera ce nombre, de telle sorte que le numéro pris soit à coup sûr unique.
Par contre, pour un compteur, on préférera une variable d'instance : on veut disposer d'une série de compteurs indépendants. Incrémenter la valeur d'un ne peut pas changer la valeur d'un autre.
I-B-4. Méthodes▲
La même distinction existe pour les méthodes : un méthode de classe ne peut qu'utiliser des variables de classe, tandis que les méthodes d'instance peuvent également accéder aux variables de l'objet.
Les méthodes d'instances sont identiques entre les objets, elles n'en définissent pas l'état : leur code est partagé par toutes les instances d'une classe.
I-C. Développement de programmes orientés objet▲
I-C-1. Tâches de développement▲
De manière générale, on développe un programme orienté objet en suivant les tâches suivantes, répétées itérativement :
- Isoler un ensemble de scénarios qui décrivent le comportement souhaité dans une série de situations représentatives de son utilisation ;
- Identifier des composants du système ;
- Attribuer à chaque composant ses responsabilités et en organiser la délégation.
Chaque composant aura un ensemble simple et bien défini de responsabilités ; on tentera de limiter l'interaction entre les composants pour favoriser la modularité.
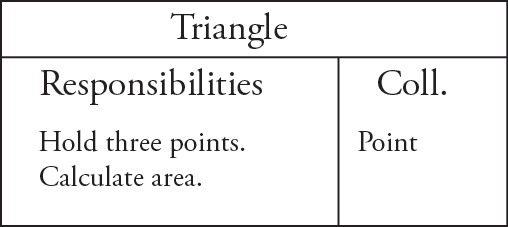
I-C-2. Cartes CRC▲
On peut décrire sur une carte CRC (composant, responsabilités, collaborateurs) l'utilité du composant, ses responsabilités, les interactions qu'il devra avoir. Chaque carte devra rester simple, on ne peut pas y donner les détails du système (la place disponible sur la carte n'est pas extensible : si on arrive à court de place, il vaut probablement mieux scinder le composant) ; ces cartes sont plastifiées : on peut effacer et réécrire à l'envi, en fonction de l'évolution de l'étude des scénarios.
Par exemple, on peut vouloir représenter un triangle à partir de trois points ; la seule fonctionnalité qui sera requise dans cette application en sera le calcul d'aire. On aura un seul collaborateur : le point, qui sera responsable de son côté du stockage de ses coordonnées. Le triangle en utilisera trois (fournis lors de sa construction) pour calculer la hauteur.
On peut également utiliser une carte pour le point.
I-D. Héritage▲
Jusqu'à présent, on considérait qu'un programme orienté objet était constitué d'une série de définitions de classes indépendantes que l'on instanciait. Ces classes indépendantes donnaient toujours des objets identiques à l'exécution ; pour changer la nature d'un objet, il fallait utiliser une classe totalement différente. Cependant, on pourrait partager du code entre plusieurs classes, à l'aide d'une approche intermédiaire : des objets pas forcément identiques ou différents, mais avec une série de caractéristiques communes.
I-D-1. Hiérarchie de classes▲
On définit ainsi une hiérarchie des classes, qui lie entre elles les classes composant un programme orienté objet. Les descendants d'une classe (sous-classes) sont des spécialisations, les classes parentes seront les généralisations.
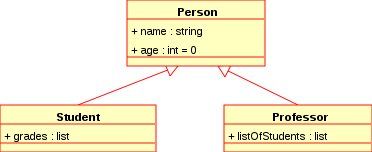
L'héritage est un mécanisme associé à cette hiérarchie : une sous-classe hérite par défaut des mêmes variables et méthodes que ses parents, tout en gardant la possibilité de définir de nouvelles variables ou méthodes ou de remplacer les éléments hérités par des éléments propres. L'héritage est transitif : si une classe est une généralisation d'une autre, alors cette autre est une spécialisation de la première.
Par conséquent, on dispose du polymorphisme des objets : l'interface d'une sous-classe inclut nécessairement celles de ses parents, on peut utiliser un objet d'une classe enfante comme s'il était instancié de la classe parente.
Il est aussi intéressant de définir des classes abstraites, quine sont pas destinées à être instanciées mais à fournir des éléments à hériter. Une telle classe ne doit pas forcément fournir un corps pour chaque méthode définie, les méthodes sans corps sont alors appelées « méthodes abstraites ». En cas d'héritage, ces méthodes abstraites devront être implémentées. Une classe abstraite permet de factoriser du code et de mettre une interface en évidence : au lieu de réécrire le code, on hérite de cette classe abstraite ; toute classe en héritant disposera d'au moins une certaine interface.
I-D-2. Principe de substitution de Liskov▲
Une sous-classe doit être utilisable dans toutes les situations où ses classes parentes peuvent l'être, sans qu'il soit possible de percevoir une différence.
Dans ce cas, la sous-classe est bien une version spécialisée de la classe parente, un sous-type du type de données défini par les classes parentes. Il s'agit du but premier de l'héritage, bien que d'autres utilisations soient possibles.
I-D-3. Visibilité▲
Sans héritage, deux visibilités ont été étudiées : public et privé. On peut exposer des méthodes supplémentaires aux classes enfants grâce à la visibilité protégée : tout ce qui est marqué protégé n'est visible que par les sous-classes. En UML, elle est notée par un carré (#).
Une classe possède ainsi deux interfaces : une interface publique, envers ceux qui instancieront la classe ; une interface protégée, envers ceux qui spécialiseront la classe.
I-D-4. Utilisations fréquentes▲
Toutes ces utilisations ne sont pas à conseiller, certaines sont cependant le seul recours quand on ne peut pas modifier la hiérarchie des classes.
- Spécialisation : une instance de la sous-classe représente un cas particulier d'instance de ses classes parentes. Cette utilisation garantit l'application du principe de substitution, tout en partageant du code.
- Spécification : une classe définit un comportement qu'elle n'implémente pas. On impose par là une interface commune, pas forcément du code commun, ce qui impose le respect du principe de substitution.
- Construction : une sous-classe fait usage des opérations implémentées par ses classes parentes sans en constituer un sous-type. Cette approche est suivie pour modifier l'interface d'une classe tout en gardant l'interface précédente. Le principe de substitution n'est pas satisfait, il vaut mieux utiliser la composition que l'héritage.
- Généralisation : une sous-classe modifie ou remplace entièrement certaines des opérations héritées afin de les rendre plus générales. On prend la hiérarchie à rebrousse-poil, ce qui viole explicitement le principe de substitution ; cet usage est réservé aux cas où il est impossible de faire autrement.
- Extension : une sous-classe ajoute de nouvelles opérations à celles héritées, sans modifier les opérations héritées. On ne viole pas le principe de substitution, on se situe à proximité de la spécialisation.
- Limitation : une sous-classe restreint les modalités d'utilisation de certaines opérations héritées de ses classes parentes. Les sous-classes ne sont pas des sous-types, il vaut mieux utiliser la composition.
- Variation : une sous-classe et sa parente directe constituent chacune une variante l'une de l'autre, le sens de la relation hiérarchique étant choisi arbitrairement. Il vaut mieux préférer une interface commune, car on viole le principe de substitution.
- Combinaison : une sous-classe hérite des éléments de plus d'une classe parente directe. La relation de hiérarchie des classes n'est plus alors forcément un arbre, il s'agira d'un graphe dirigé (acyclique de préférence). Des ambiguïtés sont possibles si plusieurs classes parentes définissent des éléments de même nom ; un élément peut être hérité de manière transitive d'une classe en suivant plusieurs chemins distincts dans le graphe de hiérarchie. Quel code faut-il exécuter ? Quels constructeurs appeler, dans quel ordre ? Comment résoudre un conflit de noms - une méthode possédant le même nom, les mêmes arguments mais des types de retour différents ?
II. Environnement de programmation Java▲
II-A. Bases du langage▲
L'environnement de programmation Java est basé sur quelques principes : la sémantique du langage est indépendante du matériel, la compilation produit un code intermédiaire qui sera interprété sur des machines virtuelles (dans le cas général : Java n'est qu'un langage, dont l'implémentation la plus répandue - développée par Sun, racheté par Oracle - se base sur du code intermédiaire, compilé en langage machine lors de l'exécution par la machine virtuelle Java ; d'autres implémentations existent, comme celle d'IBM, d'Apache ou de GNU, la dernière étant nommée GCJ, se base sur GCC et peut compiler en code intermédiaire ou machine). Le langage dispose également d'une bibliothèque standardisée.
II-A-1. Définition de classe▲
Une définition de classe est composée de deux parties : une déclaration (nom de la classe et caractéristiques) et un corps. La déclaration ressemble à ceci :
[visibility] class ClassNamePar convention, le nom de la classe s'écrit en CamelCase : on prend les mots formants le nom de la classe et on met une majuscule à la première lettre de chacun.
Le qualificateur de visibilité public (visibilité publique) spécifie que la classe peut être utilisée par toute autre partie du programme (par défaut, uniquement dans le module courant). Pour les classes internes, on peut également utiliser les marqueurs protected et private (respectivement, ces mots-clés correspondent aux visibilités protégée et privée).
Le corps de la classe contient notamment les déclarations des variables de classe et d'instance et les définitions des méthodes.
II-A-2. Définition de variable d'instance ou de classe▲
Une définition de variable dans le corps d'une classe ressemble à ceci :
[visibility] [attributes] type variableName [= value];Le marqueur de visibilité peut être public (variable accessible depuis d'autres classes), private (variable accessible uniquement depuis la même classe et les objets instancié depuis cette classe) ou protected (variable accessible uniquement depuis la classe courante et celles qui en héritent ; aussi accessible des autres classes du package courant). S'il n'y en a pas, la variable est accessible par le module courant (visibilité par défaut).
Les attributs peuvent être une combinaison de static (variable de classe), final (après attribution, la valeur ne peut plus être modifiée, une propriété qui doit être vérifiable à la compilation, sans ambiguïté), transient (valeur négligeable lors de la sérialisation, elle ne fait pas partie de l'état de l'objet) et volatile (la variable peut être modifiée par des éléments extérieurs à la méthode lors de son exécution).
Le type peut être un type primitif ou une référence. Les types primitifs sont bien définis :
- entiers signés :
- sur huit bits : byte,
- sur seize bits : short,
- sur trente-deux bits : int,
- sur soixante-quatre bits : long ;
- nombres réels (IEEE 754) :
- sur trente-deux bits (simple précision) : float,
- sur soixante-quatre bits (double précision) : double ;
- caractère Unicode (seize bits) : char ;
- booléen (un bit) : boolean.
Toute valeur qui n'est pas primitive est une référence vers un objet. Le langage définit la valeur spéciale null pour les références vides. this est une référence sur l'objet courant. Un tableau, notamment, est une référence vers un vecteur de données (que ce soit un type primitif, une référence ou un tableau) :
int[][] v;À chaque type primitif correspond une classe : Integer pour int, Double pour double, Float pour float et ainsi de suite (1). À l'aide de l'autoboxing(2), on peut passer sans problème d'un type primitif à une référence équivalente : new Integer(9) et 9 sont deux expressions équivalentes (le compilateur s'occupe de la conversion et ajoute le code requis pour passer d'une forme à l'autre selon le besoin ; cependant, ce mécanisme a un revers si on n'y prête pas attention : la conversion n'est pas gratuite et le passage répété du type primitif à la référence peut avoir un impact négatif sur les performances du programme). Ce mécanisme est surtout utile pour les génériques (3).
On dispose également de classes gérant des nombres de précision arbitraire, tant entiers que décimaux : BigInteger et BigDecimal. Voir leur documentation pour plus d'informations à leur sujet.
Les types primitifs semblent voués à disparaître avec les prochaines versions de Java, en en faisant un langage complètement orienté objet
II-A-3. Déclaration de méthode▲
La forme canonique de déclaration de méthode est la suivante :
[visibility] [attributes] returnType methodName(type arg) {
// Travail utile (corps de la méthode)
}Le marqueur de visibilité est identique à celui d'une variable.
Les attributs sont déclarés à l'aide d'une combinaison de static (méthode de classe) et native (méthode implémentée en dehors de la machine virtuelle).
Le type de retour peut être un type primitif ou une référence. S'il n'y a pas de retour, le type fictif void est utilisé.
S'il n'y a pas d'argument, la liste est vide (()).
Les méthodes native n'ont pas de corps (il est remplacé par un ;).
On dispose également du polymorphisme : on peut déclarer, dans une même classe, plusieurs méthodes avec le même nom, pour autant qu'elles diffèrent par leur liste d'arguments (type et/ou nombre des arguments). Le type de retour n'intervient jamais dans la différentiation des méthode. Lors de la réception d'un message, on pourra déterminer la méthode à appeler en fonction de la liste de paramètres.
Les paramètres d'une méthode sont toujours passés par valeur, pas par variable (le type ou la référence) : quand on passe en paramètre une instance d'une classe, on passe la valeur de la référence.
II-A-4. Groupes de classes▲
Un programme orienté objet est un ensemble de définitions de classes ; pour structurer l'application, il est préférable de les encapsuler dans un groupe de classes (package). On tentera au maximum de limiter un groupe à une identité fonctionnelle propre et de les découpler autant que possible.
Ces groupes sont eux-mêmes organisés dans une architecture arborescente où les noms doivent être uniques. À cette fin, les noms de groupes seront constitués d'une suite d'indicateurs séparés par des points.
Pour définir l'appartenance à un groupe, on utilise le mot-clé package en début de fichier source (cette instruction doit être la première de la classe) ; de plus, la structure des fichiers doit correspondre au groupe (le contenu du groupe netscape.javascript doit se trouver dans le dossier netscape/javascript).
package netscape.javascript;
public class Interpreter {
// ...
}Pour accéder au contenu d'un groupe, on doit spécifier le nom complet de la classe, groupe y compris (netscape.javascript.Interpreter), ou bien importer les classes à l'aide du mot-clé import (il s'agit d'un sucre syntaxique pour éviter de taper le nom du groupe à chaque fois qu'on utilise la classe). Le groupe java.lang est toujours automatiquement importé.
package netscape.browser;
import netscape.javascript.Interpreter;
import netscape.javascript.*;
public class Window {
// ...
}Les groupes introduisent un nouveau niveau de visibilité, qui n'utilise pas de mot-clé : la visibilité de groupe, toutes les classes du même groupe ont accès à la classe ou aux méthodes sans niveau d'accès précisé. De même, les éléments protected seront également accessibles depuis le groupe courant.
Dans un programme réel, utiliser des groupes de classes n'est pas facultatif, il vaut mieux prendre l'habitude de les utiliser dès les premiers essais en Java.
II-B. Messages, instanciation et initialisation des objets▲
II-B-1. Message▲
Un message est une requête transmise à un objet ou à une classe de manière synchrone afin d'effectuer une certaine opération en fonction de certains paramètres éventuels. Il peut renvoyer une valeur.
II-B-2. Création d'objet▲
Pour créer un objet, on évalue une expression de l'opérateur new :
new Class()Cette évaluation provoquera l'instanciation de l'objet et renvoie une référence vers l'objet nouvellement créé.
En particulier, on peut instancier des tableaux :
new type[expression]...[expression][]...[]II-B-3. Constructeur▲
À l'instanciation, les variables d'instances sont initialisées à l'aide des expressions définies dans leur déclaration. Si on veut exécuter des instructions plus complexes, on utilise le mécanisme du constructeur :
[visibility] Class(argument, argument...) { ... }On peut définir plusieurs constructeurs (polymorphisme) ; par défaut, toute classe dispose d'un constructeur par défaut vide (si on définit un seul autre constructeur, il ne sera pas créé par le compilateur) ; on peut également chaîner les constructeurs, à condition qu'on n'appelle qu'un seul autre constructeur et qu'il s'agisse de la première instruction.
[visibility] Class(argument, argument...) {
this(expression, expression...);
// ...
}Ce mécanisme de constructeur permet de s'assurer que du code a été exécuté si l'objet a été instancié.
De même, on peut définir des blocs statiques d'initialisation, qui initialiseront les classes à leur chargement :
[visibility] class Class {
// ...
static {
// ...
}
// ...
}On peut en définir plusieurs par classe, ils seront exécutés l'un après l'autre dans leur ordre de définition.
II-B-4. Destruction▲
La destruction des objets est gérée exclusivement par le garbage collector, qui libère automatiquement la mémoire des objets qui ne sont plus accessibles (il travaille de manière asynchrone tant que l'exécution du programme peut se poursuivre : on ne peut jamais être sûr du moment de la destruction d'un objet).
II-B-5. Exécution d'un programme▲
Pour exécuter une application autonome, on doit définir une classe publique contenant une méthode main statique et publique :
[visibility] class Class {
// ...
public static void main(String[] args) {
// ...
}
// ...
}II-C. Héritage▲
On déclare qu'une classe est une sous-classe directe d'une autre classe à l'aide du mot-clé extends. L'héritage multiple de classes n'est pas autorisé. La classe Object est au sommet de la hiérarchie.
[visibility] class ClassS extends ClassG {
// ...
}Une classe déclarée final ne peut pas être héritée ; les méthodes final ne peuvent pas être surchargées :
[visibility] final class ClassS extends ClassG {
// ...
final void method() {
// ...
}
}Une classe ou une méthode est déclarée abstraite par le mot-clé abstract :
[visibility] class ClassS extends ClassG {
// ...
abstract void method() {
// ...
}
}II-C-1. Polymorphisme des objets▲
Ce mécanisme peut mener à des situations ambiguës, résolues différemment pour les méthodes et les variables d'instance.
Pour les méthodes, le code à appeler sera déterminé de manière dynamique : par le type de l'objet instancié.
Pour les variables d'instance, la variable référencée sera déterminée de manière statique : par le type de la référence sur l'objet instancié.
En effet, une lecture ou écriture de variable ne prend pas beaucoup de temps, alors que la recherche de la variable correspondante dans l'objet requiert la recherche dans une structure de données : il serait très lourd d'écrire dans une variable, puisque le temps de la recherche ne sera pas compensé par le temps de l'opération. A contrario, pour une méthode, on suppose qu'il y aura une certaine quantité de code à exécuter, qui prendra nettement plus de temps que la résolution du bout de code à exécuter.
II-C-2. Accès aux éléments de la classe parente▲
Définir une nouvelle variable d'instance ou de classe dans une sous-classe avec le même nom qu'une variable de la classe parente reviendra à masquer la première variable ; on peut toutefois y accéder par le mot-clé super (ou par un cast de this avec ((ParentClass) this).member).
Cependant, il vaut mieux éviter d'avoir des variables d'instance ou de classe qui ont le même nom que celles de la classe parente, pour des raisons de lisibilité.
Pour les méthodes, tout s'effectue de manière dynamique : caster this n'aura aucun effet, il faut utiliser super.
II-C-3. Constructeurs▲
Dans les sous-classes, il est nécessaire que les constructeurs appellent les constructeurs des parents, par chaînage des constructeurs, pour s'occuper de la partie parente. Par défaut, le constructeur appelle le constructeur par défaut de la classe parente, sans argument, comportement que l'on peut surcharger à l'aide du mot-clé super (chaînage des constructeurs).
II-C-4. Interfaces▲
En Java, il est possible d'hériter de plusieurs interfaces, une forme très allégée de l'héritage multiple où on n'hérite que des éléments d'interface, pas de code. Cependant, cette forme d'héritage multiple souffre de défauts communs avec l'héritage multiple classique : il n'est pas possible d'implémenter plusieurs interfaces qui ont un conflit de noms (plusieurs méthodes ont la même signature mais des types de retour différents, sans compter les exceptions).
Une interface Java est une classe définissant une collection de déclarations de méthodes publiques sans implémentation et de constantes publiques.
interface Interface {
type method(type arg);
// ...
type name = value;
// ...
}On peut établir une relation hiérarchique entre classes et interfaces : une classe peut implémenter une ou plusieurs interfaces à l'aide du mot-clé implements.
class ClassI implements I1, I2 {
// ...
}Un graphe d'héritage peut également être établi entre les interfaces à l'aide du mot-clé extends.
interface Interface extends I1, I2 {
// ...
}On peut définir des interfaces vides, dont l'implémentation représente l'engagement à se conformer à certaines règles de comportement et de structure.
II-D. Gestion des erreurs et exceptions▲
Lors de l'exécution, des situations exceptionnelles peuvent se produire (dépassement arithmétique, division par zéro, insuffisance mémoire, erreur d'entrée/sortie, etc.), des cas où l'on doit interrompre l'exécution de la méthode. Plusieurs manières de procéder sont possibles : retourner un code d'erreur ou une valeur par défaut, par exemple. On doit toujours libérer les ressources (destruction d'objets, fermeture de fichiers, etc.), il faut donc prévoir du code spécifique pour gérer ces cas en plus des retours d'erreurs, ce qui fait un code très long et très répétitif.
On souhaite donc, autant que possible, découpler le code utile de la gestion des erreurs, pour éviter de dupliquer inutilement cette gestion et permettre une lecture aisée du code.
On utilise ainsi le mécanisme d'exceptions : une exception est un signal indiquant qu'une situation exceptionnelle s'est produite. En Java, ce signal prend la forme d'un objet instancié au moment de la situation exceptionnelle, dans une zone mémoire réservée à l'avance (le new pourrait échouer par manque d'espace mémoire, on ne peut pas espérer qu'il reste assez de mémoire pour ce traitement). On transfère alors le contrôle à un segment de code particulier dans la méthode s'il existe ou à la méthode appelante.
Java implémente ainsi les exceptions par le modèle d'interruption : on ne peut pas retourner au point où l'exécution a été stoppée à cause de l'exception, même si on a corrigé la situation. On peut cependant émuler le modèle de reprise en lançant une méthode qui tente de corriger le problème au lieu de lancer une exception à l'appelant ; il faut alors utiliser une boucle, pour réessayer l'exécution du code une fois que l'erreur potentielle a été corrigée (il faut s'assurer qu'elle se termine).
II-D-1. Types d'exceptions▲
Java distingue deux types d'exceptions : les exceptions d'exécution, pouvant arriver n'importe où sans qu'il soit utile ou faisable de les gérer particulièrement (erreur arithmétique, dépassement d'un tableau, insuffisance mémoire, etc.) ; les exceptions contrôlées, rencontrées dans des opérations particulières dont on peut récupérer plus facilement (lecture de fichier interrompue, mauvais format de données, etc.). Une autre catégorie d'exceptions existe : les erreurs, dont il est strictement impossible de récupérer (erreur au niveau de la machine virtuelle ou du système).
Toutes les exceptions doivent hériter de la classe Throwable, comme Error et Exception. Parmi les classes enfantes de Exception, on trouve RuntimeException, dont les classes enfantes sont les exceptions d'exécution, pas forcément contrôlées ; toutes les autres classes héritant de Throwable sont des exceptions contrôlées. Vu la gravité des exceptions de type Error, elles ne doivent pas être contrôlées.
II-D-2. Traitement des exceptions▲
Pour traiter les exceptions, on place le code dans un bloc try : ce code sera exécuté jusqu'à ce qu'une exception survienne ; les exceptions seront récupérées dans les blocs catch suivants ; le code du bloc finally est toujours exécuté, qu'il y ait eu ou non exception, avant un return s'il y en a avant. Seul le bloc try est obligatoire dans cette construction, les deux autres peuvent être omis.
try {
// Code pouvant lancer une exception (partie utile).
}try {
// Code pouvant lancer une exception (partie utile).
}
catch(Exception1 e) {
// Code de gestion des exceptions de type Exception1.
}
catch(Exception2 e) {
// Code de gestion des exceptions de type Exception2.
}
// ...try {
// Code pouvant lancer une exception (partie utile).
}
catch(Exception1 e) {
// Code de gestion des exceptions de type Exception1.
}
catch(Exception2 e) {
// Code de gestion des exceptions de type Exception2.
}
// ...
finally {
// Code toujours à exécuter, qu'une exception ait été lancée ou pas.
}Il n'est pas toujours possible de traiter toutes les exceptions de la sorte : elles sont alors transmises à la méthode appelante, jusqu'à ce qu'une clause catch appropriée soit rencontrée. Si l'exception remonte jusqu'à la machine virtuelle, une erreur est transmise à l'utilisateur. Toute méthode doit spécifier (à l'aide du mot-clé throwsAuteur inconnu2012-07-16T16:29:22.91throw ou thows ou thrown ?Unknown Author2012-07-17T14:27:15.92Reply to Auteur inconnu (16/07/2012, 16:29): "..."On déclare avec throws, on lance avec throw, thrown n'est pas un mot-clé.) les exceptions contrôlées qui peuvent survenir sans être récupérées (y compris les constructeurs) :
type method(type arg) throws Exception1, Exception2 {
// ...
}Pour lancer une exception, on utilise le mot-clé throw.
type method(type arg) throws Exception {
throw new Exception("Message.");
}Ainsi, pour définir une nouvelle exception, on doit hériter de la classe Throwable (on hérite de préférence de Exception) et fournir deux constructeurs, un sans argument et un avec une chaîne de caractères :
class NewException extends Exception {
public NewException() {
super();
}
public NewException(String s) {
super(s);
}
}On peut également définir un constructeur pour le chaînage des exceptions, il prend en paramètre une exception. Il sert, par exemple, lorsqu'on a reçu une exception d'un composant sous-jacent de bas niveau et qu'on souhaite renvoyer une exception de plus haut niveau sans perdre les informations apportées par la première exception.
Une bonne pratique est de définir les mêmes constructeurs que la classe Throwable, soit un constructeur par défaut (sans argument), avec un message, avec une cause (le chaînage), ainsi qu'avec cause et message.
II-E. Clonage▲
Puisque l'accès aux objets se fait par l'intermédiaire de références, copier une telle valeur ne duplique pas les objets, on dispose juste d'une variable supplémentaire pour accéder à l'objet (si son état ne peut pas être modifié, cela suffit largement).
Par contre, si l'état peut changer, on ne peut pas se limiter à copier les références, on doit instancier un nouvel objet et y recopier les variables d'instance. Dans le cas d'un clonage superficiel, on se limitera à recopier les références sur les objets que cet objet pourrait contenir ; pour un clonage en profondeur, le nouvel objet disposera de copies de tous les objets référencés par son modèle.
Ce mécanisme permet donc d'outrepasser les principes de base de la programmation orientée objet en autorisant la création d'objets sans passer par un constructeur.
En Java, cette opération s'effectue par l'envoi d'un message clone(), qui renverra un référence vers le clone créé. Cette méthode est implémentée dans Object, mais est protégée et renvoie une exception pour toutes les classes qui n'implémentent pas l'interface Cloneable. Pour la rendre opérationnelle, il faut donc implémenter cette interface et définir une méthode clone publique, ce qui est un gage que la classe réagira correctement à cette opération :
public Object clone() {
try {
return (Object) super.clone();
} catch(CloneNotSupportedException e) {
throw new InternalError(e);
}
}Une erreur à éviter est de retourner la référence obtenue par création avec new d'un objet : si on autorise l'héritage de la classe, toute sous-classe ne pourrait que retourner des objets de la classe qui a mal implémenté clone(), c'est un grand frein à l'héritage. A contrario, l'implémentation fournie par Object renvoie un objet instancié depuis la bonne classe, peu importe sa place dans la hiérarchie (le type d'objet à créer est déterminé dynamiquement).
Une fois qu'on a obtenu un clone superficiel de l'objet par super.clone(), il faut copier les autres champs qui doivent l'être en appelant la méthode clone() de ces objets.
Il faut noter que le simple fait d'implémenter l'interface Cloneable ne rend pas une classe clonable par quiconque : il faut en plus s'assurer que la méthode clone() est bien publique.
II-F. Équivalence▲
Quand on compare des objets, on a deux choix : soit l'opérateur ==, qui compare les valeurs des références ; soit la méthode equals() (publique et héritée de Object), qui peut être redéfinie pour proposer un test d'égalité plus poussé entre deux objets, en définissant une relation d'équivalence bien dressée (par défaut, elle effectue le test le plus discriminant possible et le seul possible sur tous les objets : la comparaison des références).
Le booléen retourné par equals() doit respecter certaines propriétés, les trois premières étant héritées des relations d'équivalences définies sur des algèbres :
- Réflexivité : pour tout x, x.equals(x) doit retourner true ;
- Symétrie : pour tous x et y tels que x.equals(y), alors y.equals(x) doit retourner true ;
- Transitivité : pour tous x, y et z tels que x.equals(y) et y.equals(z), alors x.equals(z) doit retourner true ;
- Cohérence : tant que les objets référencés par x et y ne changent pas d'état, alors x.equals(y) ne peut pas changer de valeur ;
- Comparaison au vide : pour tout x, x.equals(null) doit retourner false.
Le compilateur ne peut pas vérifier que ces propriétés sont respectées : réimplémenter cette méthode est équivalent à signer un contrat de respect de ces propriétés.
Pour implémenter cette méthode, on devra notamment utiliser l'opérateur instanceof (afin de respecter le principe de substitution de Liskov, on ne peut pas se baser simplement sur le nom de la classe) ; propriété intéressante : pour toute référence kitxmlcodeinlinelatexdvpxfinkitxmlcodeinlinelatexdvp non nulle, x instanceof null est faux : on peut donc effectuer un test très discriminant et respecter la cinquième condition très rapidement. Pour compléter l'implémentation, on caste l'objet à comparer et on compare champ par champ tout ce qu'il est nécessaire de comparer.
@Override public boolean equals(Object o) {
if(! (o instanceof Class)) {
return false;
}
Class c = (Class) o;
return c.field.equals(field) && c.field2.equals(field2);
}Si on redéfinit equals(), on doit réimplémenter hashCode(), qui fournit un hash entier utilisé par les tables de hachage disponibles dans la bibliothèque standard, à cause du contrat signé par la réimplémentation de cette méthode (voir la documentation). La seule contrainte absolue à respecter est que, pour tous x et y tels que x.equals(y) retourne true, les valeurs calculées par x.hashCode() et y.hashCode() doivent être égales. A contrario, l'égalité des hashes ne garantit pas l'égalité des objets selon equals(). Pour garantir autant que possible l'efficacité des tables de hachage, il est préférable d'assurer une distribution uniforme des valeurs de hachage dans l'ensemble des valeurs entières (on travaille en arithmétique modulo kitxmlcodeinlinelatexdvp2^{31}-1finkitxmlcodeinlinelatexdvp).
II-G. Sérialisation▲
La sérialisation est un mécanisme rassemblant toutes les informations caractérisant un objet (sa classe, son état, ainsi que les informations caractérisant tous les objets vers lesquels il a une référence ; les cycles de dépendances sont automatiquement gérés). Grâce à elle, on peut stocker un objet pour le récupérer à une prochaine exécution du programme ou pour le transmettre à un autre programme, l'opération inverse, la désérialisation, recréant l'objet tel qu'il a été sauvé (il s'agit donc d'un autre mécanisme extralinguistique qui permet la création d'objets sans passer par un constructeur).
Pour sérialiser un objet, on utilise la méthode writeObject() de ObjectOutputStream ; pour l'opération inverse, la désérialisation, on utilise la méthode readObject() de ObjectInputStream. Seules les instances de classes implémentant l'interface Serializable sont concernées, puisque cette opération n'a pas forcément un sens pour toutes les classes. La valeur des variables déclarées transient n'est pas incluse (elles ne font pas partie de l'état de l'objet, probablement parce qu'il s'agit d'une version redondante des informations déjà présentes sous une autre forme afin d'optimiser certains traitements - par exemple, un tampon).
Il faut s'assurer que les programmes qui sérialiseront et désérialiseront la classe en possèdent la même version : si une version plus récente dispose de champs supplémentaires qui ne sont pas sérialisés, le mécanisme ne peut pas en inventer les valeurs et il renvoie donc une exception, ceci afin d'éviter toute incohérence. Ce mécanisme est donc prompt à échouer (si on tente de charger un fichier qui n'est pas une sérialisation de la classe attendue ou pas du tout une sérialisation, l'opération ne peut pas réussir).
III. Conclusion▲
On a vu que l'approche orientée objet facilite l'écriture et la maintenance du code, notamment grâce à une modularité plus facile à implémenter qu'avec d'autres paradigmes de programmation. Cependant, cela ne signifie absolument pas que cette manière de procéder soit la meilleure dans tous les cas ; en ce qui concerne la programmation concurrente, d'aucuns considèrent que d'autres paradigmes sont plus appropriés, comme la programmation fonctionnelle (cette dernière encourage à ne pas disposer d'état : appliquée aux objets, on remarque que les valeurs stockées ne sont affectées que lors de la création de l'objet, il n'est plus possible d'en changer les valeurs ; ainsi, il n'y a plus de risque que deux processus écrivent simultanément dans un objet au risque de le corrompre s'il n'est pas prévu à cet effet).
Il faut cependant remarquer que cette approche orientée objet, surtout en Java, est très répandue de par le monde, dans de grandes sociétés et de gros logiciels.
IV. Remerciements▲
Cet article se base essentiellement sur le cours oral de programmation orientée objet de Bernard Boigelot (INFO0062), donné à l'ULg pendant l'année académique 2011-2012. Les livres Thinking in Java, quatrième édition, de Bruce Eckel et Programmation orientée objet, cinquième édition, de Hughes Bersini ont été utilisés comme compléments occasionnels.
Merci à Nemek, Mikael Baron et Thierry Leriche-Dessirier pour leurs commentaires techniques ; merci à ram-0000 pour sa relecture orthographique.