


V. La mémoire▲
V-A. La mémoire partagée et les conflits▲
Lorsque nous avons commencé à travailler sur la mémoire partagée, vous n'aviez pas encore beaucoup de connaissances en CUDA, vous n'auriez pas pu comprendre cette section. C'est pourquoi elle est placée ici.
Parce qu'elle est sur la carte elle-même, la mémoire partagée est plus rapide que la mémorie locale et que la mémoire globale. En fait, pour tous les threads d'un warp, y accéder est aussi rapide que pour un registre, tant qu'il n'y a pas de conflit de mémoire entre les threads.
Pour obtenir une bande passante assez haute, la mémoire partagée est divisée en modules de même taille, les banques, auxquelles on peut accéder simultanément. Ainsi, toutes les requêtes en lecture ou écriture faites en n adresses différentes qui tombent dans n banques différentes peuvent être effectuées simultanément, ce qui résulte en une bande passante effective n fois plus élevée que la bande passante d'un seul module.
Cependant, si deux adresses tombent dans la même banque, il y a un conflit de banque et les accès doivent être sérialisés. Le matériel divise une requête en mémoire avec conflits automatiquement en autant de requêtes non conflictuelles que nécessaire. Ceci fait décroître la bande passante effective d'un facteur égal au nombre de requêtes en mémoire à effectuer. Si le nombre de requêtes séparées est de n, la requête en mémoire peut causer jusqu'à n conflits.
Pour des performances maximales, il est donc très important de comprendre comment les adresses mémoire sont associées aux banques, pour pouvoir prévoir les requêtes pour minimiser les conflits.
Dans le cas de la mémoire partagée, les banques sont organisées pour que des mots de 32 bits successifs soient assignés à des banques successives. Chaque banque a donc une bande passante de 32 bits par deux cycles d'horloge.
Pour les périphériques actuels, la taille d'un warp est de 32 threads et il y a 16 banques. Une requête en mémoire partagée pour un warp est divisée en deux requêtes : une pour la première moitié du warp et une autre pour l'autre moitié du warp. Ceci ayant pour conséquence qu'il ne peut y avoir de conflit entre les moitiés d'un warp.
Il est courant que chaque thread accède à un mot de 32 bits d'un tableau indexé, grâce à l'identifiant du thread
![]() et à une enjambée de
et à une enjambée de ![]() .
.
__shared__ float shared[32];
float data = shared[BaseIndex + s * tid];
Dans ce cas, les threads ![]() et
et
![]() accèdent à la même banque quand
accèdent à la même banque quand
![]() est un multiple du nombre de banques
est un multiple du nombre de banques
![]() , quand
, quand ![]() est
un multiple de
est
un multiple de ![]() , ou
, ou ![]() lui-même. Ceci se traduit par un conflit uniquement si
lui-même. Ceci se traduit par un conflit uniquement si ![]() est impair.
est impair.
Voici quelques requêtes qui ne produisent pas de conflit.
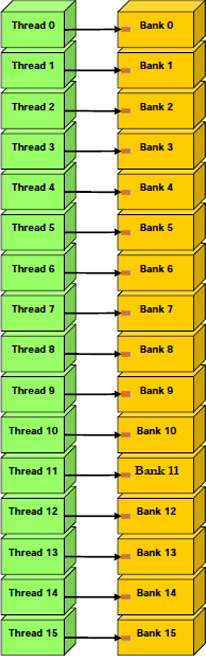
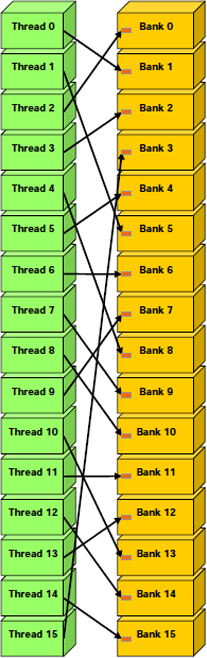
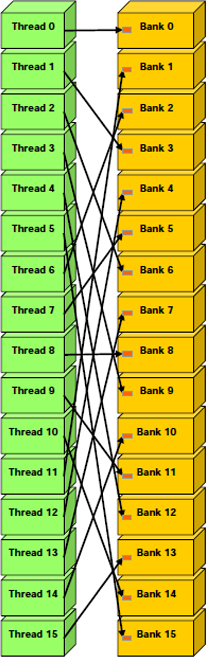
Contrairement à celles-ci.
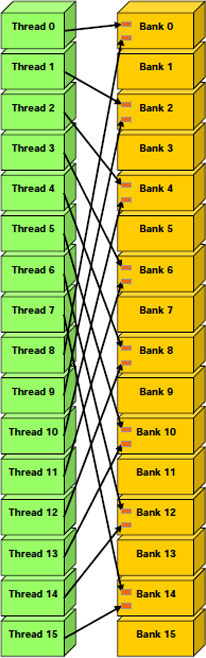
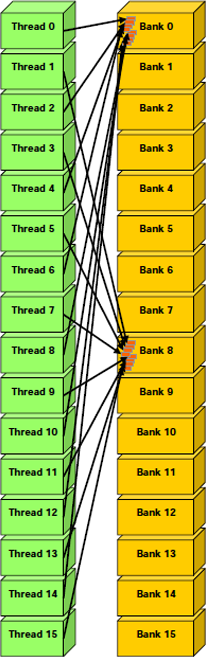
D'autres cas méritent d'être mentionnés. Par exemple, il y a conflits si un tableau de char est accédé de cette manière, parce que la taille d'un élément du tableau dépasse ou est en retrait par rapport au mot de 32 bits.
__shared__ char shared[32];
char data = shared[BaseIndex + tid];Dans cet exemple, shared[1], shared[2], shared[3] et shared[4] sont dans la même banque.
Néanmoins, lorsque l'on y accède de cette manière, il n'y a pas de conflit.
char data = shared[BaseIndex + 4 * tid];Il y a aussi des conflits pour les tableaux de double, vu que la requête en mémoire est séparée en deux requêtes séparées de 32 bits.
__shared__ double shared[32];
double data = shared[BaseIndex + tid];Une manière de l'éviter est de séparer le type en deux, de cette manière.
__shared__ int shared_lo[32];
__shared__ int shared_hi[32];
double dataIn;
shared_lo[BaseIndex + tid] = __double2loint(dataIn);
shared_hi[BaseIndex + tid] = __double2hiint(dataIn);
double dataOut = __hiloint2double(shared_hi[BaseIndex + tid],
shared_lo[BaseIndex + tid]);Cependant, ceci n'améliore pas les performances et devrait même les diminuer sur des architectures futures.
Une assignation de structure est compilée en autant de requêtes en mémoire que nécessaire pour chaque membre de la structure.
__shared__ struct type shared[32];
struct type data = shared[BaseIndex + tid];Ce code peut avoir beaucoup de résultats différents quant au nombre de requêtes nécessaires.
| Définition de type | Conflit à la lecture ? | Pourquoi ? |
|---|---|---|
| struct type { float x; float y; float z; }; | Non | Chaque membre est lu avec un enjambement d'un mot (32 bits) |
| struct type { float x; float y; }; | Non | Chaque membre est lu avec un enjambement d'un mot (32 bits) |
| struct type { float f; char c; }; | Oui | Chaque membre est lu avec un enjambement de plus d'un mot (5 octets, 40 bits) |
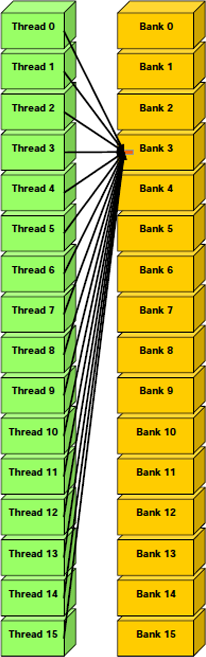
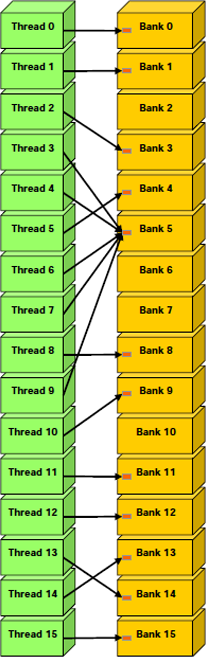
Finalement, la mémoire partagée dispose aussi d'un mécanisme de diffusion par lequel un mot de 32 bits peut être lu et diffusé à plusieurs threads simultanément, en n'effectuant qu'une seule opération de lecture. Ceci réduit le nombre de conflits quand plusieurs threads d'un demi-warp lisent une même banque, dans le même mot.
V-B. Types d'allocation▲
La mémoire, sous CUDA, peut être allouée, soit linéairement, soit sous forme de tableau.
La mémoire linéaire existe dans un espace à adresses de 32 bits. Ainsi, des entités allouées séparément peuvent se référencer l'une l'autre par des pointeurs, par exemple dans un arbre binaire.
Les tableaux sont une mémoire opaque optimisée pour la recherche dans une texture. Ils possèdent d'une à trois dimensions et sont constitués d'éléments à une, deux ou quatre composantes, qui peuvent être des entiers signés ou non sur 8, 16 ou 32 bits, ou bien des flottants sur 32 bits. Ces tableaux sont uniquement lisibles par des kernels avec des recherches dans des textures et ne peuvent être liés qu'à des références avec le même nombre de composantes.
Ces deux types sont accessibles en lecture et écriture par les fonctions de copie mémoire.
V-C. Mémoire linéaire▲
Elle est allouée avec les fonctions cudaMalloc() et cudaMallocPitch(), effacée avec cudaFree().
Ce code alloue un tableau de 256 éléments flottants en mémoire linéaire.
float* devPtr;
cudaMalloc( (void * *) & devPtr, 256 * sizeof(float) );Il existe d'autres fonctions pour l'allocation de mémoire : cudaMallocPitch() et cudaMalloc3D(), pour des tableaux en 2D et 3D. Ces fonctions permettent de s'assurer que les copies s'effectueront le plus vite possible, avec les fonctions appropriées : cudaMemcpy2D() et cudaMemcpy3D().
Ce code montre l'allocation et l'utilisation d'un tableau 2D.
float* devPtr;
int pitch;
cudaMallocPitch( (void**)&devPtr, &pitch, width * sizeof(float), height);
mykernel<<<100, 512>>>(devPtr, pitch);
__global__ void mykernel(float* devPtr, int pitch)
{
for (int r = 0 ; r < height ; ++r)
{
float* row = (float *) ( (char *) devPtr + r * pitch);
for (int c = 0 ; c < width ; ++c)
{
float element = row[c];
}
}
}Et voici pour un tableau 3D.
cudaPitchedPtr devPitchedPtr;
cudaExtent extent = make_cudaExtent(64, 64, 64);
cudaMalloc3D(&devPitchedPtr, extent);
mykernel<<<100, 512>>>(devPitchedPtr, extent);
__global__ void mykernel(cudaPitchedPtr devPitchedPtr, cudaExtent extent)
{
char * devPtr = devPitchedPtr.ptr;
size_t pitch = devPitchedPtr.pitch;
size_t slicePitch = pitch * extent.height;
for (int z = 0; z < extent.depth; ++z)
{
char * slice = devPtr + z * slicePitch;
for (int y = 0 ; y < extent.height ; ++y)
{
float* row = (float*) (slice + y) * pitch;
for (int x = 0 ; x < extent.width ; ++x)
{
float element = row[x];
}
}
}
}V-D. Tableaux CUDA▲
Ils sont alloués grâce aux fonctions cudaMallocArray() et cudaMalloc3DArray(), tandis qu'ils sont libérés grâce à cudaFreeArray(). L'allocation nécessite la création d'un descripteur de format, créé à l'aide de la fonction cudaCreateChannelDesc().
cudaChannelFormatDesc channelDesc = cudaCreateChannelDesc<float>();
cudaArray * cuArray;
cudaMallocArray(& cuArray, & channelDesc, width, height);La fonction cudaGetSymbolAddress() est utilisée pour récupérer l'adresse pointant sur la mémoire allouée pour une variable qui réside en mémoire globale. La taille peut être demandée grâce à cudaGetSymbolSize()
V-E. Copie▲
Cet exemple montre la copie d'un tableau linéaire vers un tableau CUDA.
cudaMemcpy2DToArray
(
cuArray,
0,
0,
devPtr,
pitch,
width * sizeof(float),
height,
cudaMemcpyDeviceToDevice
);Cet exemple montre la copie d'un tableau hôte vers le périphérique.
float data[256];
int size = sizeof(data);
float* devPtr;
cudaMalloc( (void**) & devPtr, size);
cudaMemcpy(devPtr, data, size, cudaMemcpyHostToDevice);Et celui-ci, vers la mémoire constante.
__constant__ float constData[256];
float data[256];
cudaMemcpyToSymbol(constData, data, sizeof(data));V-F. Résumé des fonctions de copie▲
Cette section est complémentaire : chaque type de fonction de copie reprend les paramètres et les retours des fonctions de copie de la mémoire linéaire vers la mémoire linéaire.
V-F-1. Mémoire linéaire vers mémoire linéaire▲
cudaError_t cudaMemcpy
(
void * dst,
const void * src,
size_t count,
enum cudaMemcpyKind kind
)
cudaError_t cudaMemcpyAsync
(
void * dst,
const void * src,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
)- dst : pointeur vers la destination des données ;
- src : source des données ;
- count : nombre de bytes à copier ;
- kind : direction de copie ;
- stream : flux.
kind doit être une de ces valeurs.
- cudaMemcpyHostToHost : hôte à hôte ;
- cudaMemcpyHostToDevice : hôte à périphérique ;
- cudaMemcpyDeviceToHost : périphérique à hôte ;
- cudaMemcpyDeviceToDevice : périphérique à périphérique (ces copies sont automatiquement asynchrones).
cudaMemcpyAsync est la version asynchrone de la copie. Ceci implique un respect de l'hôte. Ainsi, l'appel peut retourner avant que la copie soit terminée. Ceci ne fonctionne qu'en mémoire paginée verrouillée. Si elle n'est pas verrouillée, la fonction retourne une erreur. La copie peut être associée à un flux en en précisant un.
Ces fonctions peuvent retourner ces valeurs.
- cudaSuccess : succès de l'opération ;
- cudaErrorInvalidValue : valeur non valide ;
- cudaErrorInvalidDevicePointer : pointeur sur le périphérique non valable ;
- cudaErrorInvalidMemcpyDirection : mauvaise direction de copie.
V-F-2. Mémoire linéaire vers tableaux CUDA▲
cudaError_t cudaMemcpyToArray
(
struct cudaArray * dstArray,
size_t dstX,
size_t dstY,
const void * src,
size_t count,
enum cudaMemcpyKind kind
)
cudaError_t cudaMemcpyToArrayAsync
(
cudaArray * dstArray,
size_t dstX,
size_t dstY,
const void * src,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
)- dstArray : pointeur sur le tableau CUDA de destination ;
- dstX : abscisse de l'élément à partir duquel la copie doit être effectuée ;
- dstY : ordonnée de l'élément à partir duquel la copie doit être effectuée.
V-F-3. Matrices vers matrices▲
Les matrices sont aussi appelées tableaux 2D.
cudaError_t cudaMemcpy2D
(
void * dst,
size_t dpitch,
const void * src,
size_t spitch,
size_t width,
size_t height,
enum cudaMemcpyKind kind
)
cudaError_t cudaMemcpy2DAsync
(
void * dst,
size_t dpitch,
const void * src,
size_t spitch,
size_t width,
size_t height,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
)- dpitch : largeur de la mémoire en bytes de la matrice de la destination ;
- spitch : largeur de la mémoire en bytes de la matrice de la source ;
- width : longueur d'une ligne ;
- height : nombre de lignes.
Cette fonction peut aussi retourner cette erreur.
- cudaErrorInvalidPitchValue : valeurs de pas plus grandes que le maximum autorisé.
V-F-4. Matrices vers tableaux CUDA▲
cudaError_t cudaMemcpy2DToArray
(
struct cudaArray * dstArray,
size_t dstX,
size_t dstY,
const void * src,
size_t spitch,
size_t width,
size_t height,
enum cudaMemcpyKind kind
);
cudaError_t cudaMemcpy2DToArrayAsync
(
struct cudaArray * dstArray,
size_t dstX,
size_t dstY,
const void * src,
size_t spitch,
size_t width,
size_t height,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
);- dstArray : pointeur sur le tableau CUDA de destination ;
- dstX : abscisse de l'élément à partir duquel la copie doit être effectuée ;
- dstY : ordonnée de l'élément à partir duquel la copie doit être effectuée ;
- spitch : largeur de la mémoire en bytes de la matrice de la source ;
- width : longueur d'une ligne ;
- height : nombre de lignes.
Cette fonction peut aussi retourner cette erreur.
- cudaErrorInvalidPitchValue : valeurs de pas plus grandes que le maximum autorisé.
V-F-5. Tableaux CUDA vers mémoire linéaire▲
cudaError_t cudaMemcpyFromArray
(
void * dst,
const struct cudaArray* srcArray,
size_t srcX,
size_t srcY,
size_t count,
enum cudaMemcpyKind kind
)
cudaError_t cudaMemcpyFromArrayAsync
(
void * dst,
const struct cudaArray* srcArray,
size_t srcX,
size_t srcY,
size_t count,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
)- srcArray : pointeur sur le tableau CUDA de destination ;
- srcX : abscisse de l'élément à partir duquel la copie doit être effectuée ;
- srcY : ordonnée de l'élément à partir duquel la copie doit être effectuée.
V-F-6. Tableaux CUDA vers matrices▲
cudaError_t cudaMemcpy2DFromArray
(
void * dst,
size_t dpitch,
const struct cudaArray* srcArray,
size_t srcX,
size_t srcY,
size_t width,
size_t height,
enum cudaMemcpyKind kind
)
cudaError_t cudaMemcpy2DFromArrayAsync
(
void * dst,
size_t dpitch,
const struct cudaArray* srcArray,
size_t srcX,
size_t srcY,
size_t width,
size_t height,
enum cudaMemcpyKind kind,
cudaStream_t stream = 0
)- dpitch : largeur de la mémoire en bytes de la matrice de la destination ;
- srcArray : pointeur sur le tableau CUDA de destination ;
- srcX : abscisse de l'élément à partir duquel la copie doit être effectuée ;
- srcY : ordonnée de l'élément à partir duquel la copie doit être effectuée ;
- width : longueur d'une ligne ;
- height : nombre de lignes.
V-F-7. Tableaux CUDA vers tableaux CUDA▲
cudaError_t cudaMemcpyArrayToArray
(
struct cudaArray* dstArray,
size_t dstX,
size_t dstY,
const struct cudaArray * srcArray,
size_t srcX,
size_t srcY,
size_t count,
enum cudaMemcpyKind kind
)- dstArray : pointeur sur le tableau CUDA de destination ;
- dstX : abscisse de l'élément à partir duquel la copie doit être effectuée ;
- dstY : ordonnée de l'élément à partir duquel la copie doit être effectuée ;
- srcArray : pointeur sur le tableau CUDA de destination ;
- srcX : abscisse de l'élément à partir duquel la copie doit être effectuée ;
- srcY : ordonnée de l'élément à partir duquel la copie doit être effectuée ;
Comme vous pouvez le voir, il n'existe pas de version asynchrone de cette fonction !
VI. Les flux▲
VI-A. Définition▲
Un flux est une source de données, comme un fichier, la mémoire ou le réseau. Ceci est une définition très générale, qui s'applique à tous les domaines. Dans CUDA, il ne s'agit pas exactement de la même chose.
Pour faciliter les exécutions concurrentes entre hôte et périphérique, certaines fonctions sont asynchrones, dans le runtime (la partie de CUDA que nous apprenons) : l'application récupère le contrôle avant que les calculs soient entièrement effectués. Ainsi, il arrive fréquemment que plusieurs de ces fonctions soient en cours d'exécution en même temps : elles sont concurrentes.
Ces fonctions sont les suivantes.
- cuLaunchGrid() ;
- cuLaunchGridAsync() ;
- Les fonctions de copie suffixées Async ;
- Les copies du périphérique vers le périphérique ;
- Les appels de kernels avec des fonctions __global__.
Les applications s'occupent de la concurrence via des flux. Un flux est une séquence d'instructions, qui doivent s'exécuter dans un certain ordre. D'un autre côté, des flux peuvent arrêter leur exécution pour un autre flux.
VI-B. Création▲
Un flux est défini en créant un objet flux et en le spécifiant à un appel de kernel, ou à une copie de mémoire. Par exemple, ce code crée deux flux.
cudaStream_t stream[2];
for (int i = 0 ; i < 2 ; ++i)
cudaStreamCreate(& stream[i] );Chacun de ces flux est défini, par ce code, comme une séquence d'une copie de l'hôte au périphérique, d'un appel de kernel et d'une copie du périphérique vers l'hôte.
for (int i = 0 ; i < 2 ; ++i)
cudaMemcpyAsync(inputDevPtr + i * size, hostPtr + i * size, size, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0 ; i < 2 ; ++i)
mykernel <<< 100, 512, 0, stream[i] >>> (outputDevPtr + i * size, inputDevPtr + i * size, size);
for (int i = 0 ; i < 2 ; ++i)
cudaMemcpyAsync(hostPtr + i * size, outputDevPtr + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
cudaThreadSynchronize();Chaque flux copie sa portion du tableau hostPtr vers inputDevPtr dans la mémoire du périphérique, traite ce dernier tableau et copie le résultat outputDevPtr sur l'hôte, dans la partie correspondante de hostPtr.
cudaThreadSynchronize() est appelée à la fin pour s'assurer que tous les flux ont fini de s'exécuter avant d'essayer d'utiliser leur résultat.
cudaStreamSynchronize() peut être appelée pour synchroniser un flux précis, avec tous les autres flux qui continuent leur exécution normale.
cudaStreamDestroy() est utilisée pour la destruction d'un flux.
cudaStreamQuery() permet de vérifier que toutes les opérations du flux déjà envoyées soient bien effectuées.
Tout appel de kernel ou opération de mémoire sans le paramètre de flux ne commence qu'à la fin des autres opérations. Ces opérations sont affectées au flux 0.
VI-C. Événements▲
Les événements permettent de vérifier l'état d'avancement du flux.
Voici la création de deux événements.
cudaEvent_t start, stop;
cudaEventCreate(&start);
cudaEventCreate(&stop);Et voici une autre version du code précédent, qui permet de vérifier son état d'avancement, grâce aux événements.
2.
3.
4.
5.
6.
7.
8.
9.
10.
11.
12.
13.
14.
15.
cudaEventRecord(start, 0);
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(inputDev + i * size, inputHost + i * size, size, cudaMemcpyHostToDevice, stream[i]);
for (int i = 0; i < 2; ++i)
mykernel <<< 100, 512, 0, stream[i] >>> (outputDev + i * size, inputDev + i * size, size);
for (int i = 0; i < 2; ++i)
cudaMemcpyAsync(outputHost + i * size, outputDev + i * size, size, cudaMemcpyDeviceToHost, stream[i]);
cudaEventRecord(stop, 0);
cudaEventSynchronize(stop);
float elapsedTime;
cudaEventElapsedTime(&elapsedTime, start, stop);
cudaEventDestroy(start);
cudaEventDestroy(stop);
Ce code est assez explicite : on précise qu'un événement a lieu (ligne 1), puis on exécute les instructions (lignes 3 à 8), on enregistre qu'un autre événement a lieu (ligne 10), on attend qu'il soit émis (ligne 11), on calcule le temps écoulé entre les deux événements (lignes 12 et 13), puis on supprime les événements (lignes 14 et 15).