


V. Les mains dans le cambouis▲
Il n'y a pas de langage informatique dans lequel vous ne puissiez écrire de mauvais programme.Si vous ne savez pas ce que votre programme est censé faire, vous feriez bien de ne pas commencer à l'écrire.(Extraits de Les lois de Murphy).
V-A. Les kernels▲
Très simplement, un kernel est une fonction exécutée sur le GPU.
Il en existe différents types, qualifiés de :
- __global__ : exécuté sur le GPU, mais appelé par le CPU ;
- __device__ : exécuté et appelé par le GPU ;
- __host__ : exécuté et appelé par le CPU.
Ce dernier qualificatif n'est pas obligatoire : c'est le mode de fonctionnement par défaut.
Un kernel ne s'appelle pas de la même manière qu'une fonction. Voici un appel de fonction :
fonction(parametre, parametre);Mais avant de vous parler de l'appel d'un kernel, il faut que vous compreniez bien le mode de fonctionnement d'un GPU.
Une grille représente la totalité de la tâche à effectuer. Chaque grille peut être divisée en un ou plusieurs blocs, chacun exécutant plusieurs threads.
Un thread sur un GPU n'a pas le même sens qu'un thread sur le CPU.
Sur un GPU, il s'agit de la plus petite subdivision de la tâche à effectuer.
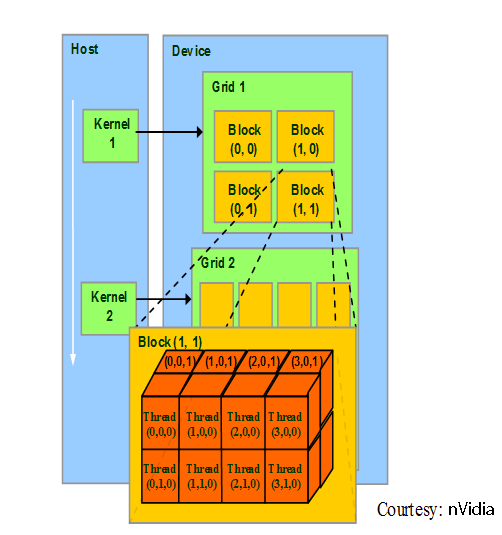
Un appel de kernel se fait en spécifiant deux paramètres entre triples chevrons précédant les paramètres passés au kernel.
kernel <<< nBlocs, threadsParBloc >>> (arguments);nBlocs est le nombre de subdivisions appliquées à la grille à calculer et est de type dim3 (le cast à partir d'un entier N initialise le dim3 à {N, 1, 1}).
threadsParBloc indique le nombre de threads à exécuter simultanément pour chaque bloc. Ici encore, cette valeur est de type dim3.
Les valeurs à appliquer dépendent simultanément du problème à résoudre (choix des dimensions des blocs) et du matériel utilisé (nombre de threads par bloc). Choisir un nombre de threads supérieur à la quantité nativement supportée entraînera une perte de performances. Cette notation permet ainsi d'adapter dynamiquement le programme aux matériels passés, présents et futurs.
Chaque kernel dispose de variables implicites en lecture seule (toutes de type dim3).
- blockIdx : index du bloc dans la grille ;
- threadIdx : index du thread dans le bloc ;
- blockDim : nombre de threads par bloc (valeur de threadsParBloc du paramétrage du kernel).
La grille est ici considérée comme un seul et unique bloc à une seule dimension.
__global__ void vecAdd(float * A, float * B, float * C)
{
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// utilisation du kernel
vecAdd<<<1, N>>>(A, B, C);
// |-> vecteurs additionnés une seule fois
// |-> nombre de composantes des vecteurs
}Dans le cas où la grille est sous-divisée en N blocs (tous d'une seule dimension), l'index pourrait être trouvé de la manière suivante.
__global__ void vecAdd(float * A, float * B, float * C)
{
int i = blockIdx.x * blockDim.x + threadIdx.x;
C[i] = A[i] + B[i];
}
int main()
{
// utilisation du kernel
const int nThreadsPerBlocks = 4;
const int nBlocks = (arraySize / nThreadsPerBlocks) + ( (arraySize % nThreadsPerBlocks) == 0 ? 0 : 1);
vecAdd<<<nBlocks, nThreadsPerBlocks>>>(A, B, C);
}Les variables doivent être qualifiées, pour définir leur lieu de résidence : voyez la section qui y est réservée.
Les paramètres entre chevrons sont requis, car le kernel est de type __global__. Si le kernel était d'un autre type, les paramètres n'auraient pas dû être précisés !
V-B. Qualifieurs de kernels▲
V-B-1. __global__▲
- Exécuté sur le périphérique.
- Appelable de l'hôte.
- Pas de récursion possible.
- Pas de variables statiques.
- Pas de liste de paramètres variables.
- On ne peut demander leur adresse mémoire.
- Incompatible avec __device__.
- Ne peut rien retourner.
- À l'exécution, on doit préciser la configuration.
- Appel asynchrone (le kernel retourne avant d'avoir effectué les calculs).
- Paramètres stockés dans la mémoire partagée, limités à 256 octets.
- Dure aussi longtemps que le kernel.
V-B-2. __device__▲
- Exécuté sur le périphérique.
- Appelable du périphérique.
- Pas de récursion possible.
- Pas de variables statiques.
- Pas de liste de paramètres variables.
- On ne peut demander leur adresse mémoire.
- Incompatible avec __global__.
- Dure aussi longtemps que l'application.
V-B-3. __host__▲
- Exécuté sur l'hôte.
- Appelable de l'hôte.
- Appliqué par défaut.
- Compatible avec __device__ (dans ce cas, le kernel pourra être exécuté sur l'hôte et sur le périphérique).
- Incompatible avec __global__.
- Dure aussi longtemps que le kernel.
V-C. Configuration de l'exécution▲
Ceci n'est requis que pour les kernels __global__ ! Requis signifie bien que l'on ne peut s'en passer, sans quoi rien ne fonctionne (avec, à la clé, beaux plantages) !
Cette configuration doit être passée entre triples chevrons avant les paramètres.
//Définition du kernel
__global__ void func(float * parameter);
//Utilisation du kernel
func <<< Dg, Db, Ns, S >>> (parameter);V-C-1. Dg▲
- Type : dim3.
- Utilité : spécifier la taille et la dimension de la grille (le produit des trois composantes est le nombre de blocs lancés).
- Remarque : z n'est pas encore utilisé et doit valoir 1.
V-C-2. Db▲
- Type : dim3.
- Utilité : spécifier la taille et la dimension de chaque bloc (le produit des trois composantes est le nombre de threads par bloc).
V-C-3. Ns▲
- Type : size_t.
- Utilité : spécifier le nombre d'octets en mémoire partagée alloués dynamiquement par bloc en plus de la mémoire allouée statiquement.
- Remarque : paramètre optionnel, valeur par défaut : 0.
V-C-4. S▲
- Type : cudaStream_t.
- Utilité : spécifier le flux associé.
- Remarque : paramètre optionnel, valeur par défaut : 0.
- La notion de flux sera abordée plus tard : sachez simplement qu'il s'agit d'une suite d'éléments de même type (comme une texture).
V-D. Qualificateurs de variables▲
V-D-1. __device__▲
Cette variable est et restera sur le périphérique. Elle ne vivra pas plus longtemps que l'application et est accessible à tous les threads de la grille et à l'hôte grâce au runtime.
Ce type peut se marier avec un des deux suivants.
V-D-2. __constant__▲
Ce type peut être utilisé avec __device__.
La variable restera en mémoire constante. Elle ne vivra pas plus longtemps que l'application et est accessible à tous les threads de la grille et à l'hôte par le runtime.
Ces variables ne peuvent être déclarées que de l'hôte, pas du périphérique !
V-D-3. __shared__▲
Ce type peut être utilisé avec __device__.
La variable résidera dans la mémoire partagée et ne survivra pas au bloc. Elle ne sera accessible qu'aux threads du bloc.
Avant que les modifications soient écrites dans la variable et visibles pour tous les autres threads, il faut appeler __syncthreads();. À noter que cet appel ne sert qu'à le garantir, il est possible que les modifications soient visibles avant.
extern __shared__ float shared[];Quand la variable est déclarée en tant que tableau externe, comme précédemment, sa taille sera fixée à l'exécution. Toutes les variables déclarées de cette manière ne sont pas contiguës : le premier bit de la première correspond au premier bit des autres, contrairement aux autres langages comme le C ou le C + +.
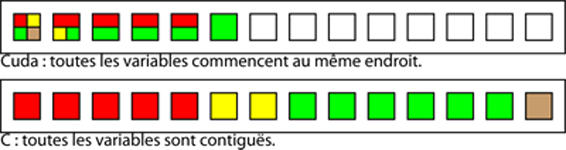
C'est pourquoi il faut préciser l'offset de début. Pour avoir l'équivalent de ce premier code, il faut écrire le contenu du second.
short array0[128];
float array1[64];
int array2[256];extern __shared__ char array[];
__device__ void func() // kernel __device__ ou bien __global__
{
short* array0 = (short*) array;
float* array1 = (float*)&array0[128];
int * array2 = (int*) &array1[64];
}Ceci est le seul moyen d'utiliser le mot-clé extern sur des variables : tous les autres emplois sont interdits.
Ces variables ne peuvent pas être initialisées en même temps que leur déclaration !
Si nous avions utilisé le premier code dans CUDA, en écrivant une valeur dans le premier tableau, une partie de cette variable aurait été imputée au deuxième et au troisième tableau. Ce qui pourrait donner des résultats très aberrants.
V-D-4. Généralités▲
Ces paramètres ne sont pas permis sur des unions ou des structures.
En définissant une variable __shared__ ou __constant__, elle sera définie statique.
V-E. Compilation▲
NVIDIA, dans son immense bonté, nous fournit un compilateur prévu pour CUDA. Celui-ci dispose d'une interface en ligne de commande simple et comparable à celles que nous connaissons, cl, de Visual Studio, ou gcc, l'interface de GCC. Ce compilateur, nvcc, s'occupe de toutes les étapes de la compilation.
Pour pouvoir définir les portions de code spécifiques à ce compilateur, il définit la macro __CUDACC__.
Comme dit précédemment, il s'occupe de toutes les phases de la compilation : l'assemblage, la compilation, et l'édition des liens. Vous pouvez choisir ces parties grâce à la ligne de commande.
Ce compilateur fonctionne très bien avec les Makefiles, c'est d'ailleurs cette technique qui va être ici développée, compatible avec les chaînes de compilation GNU (make) et Microsoft (nmake).
# Précise le compilateur précis à utiliser
ifdef ON_WINDOWS
export compiler-bindir := "a:/program files/microsoft visual studio 9.0/vc/bin"
endif
export NVCC := a:/cuda/bin/nvcc.exe
cpp.obj : cpp.cpp
$(NVCC) -c cpp.cpp $(CFLAGS) -o cpp.obj
c.o : c.c
$(NVCC) -c c.c $(CFLAGS) -o c.obj
cu.o : cu.cu
$(NVCC) -c cu.cu $(CFLAGS) -o cu.obj
OBJECTS = cpp.obj c.obj cu.obj
all : $(OBJECTS)
$(NVCC) $(OBJECTS) $(LDFLAGS) -o app.exe
clean :
$(RM) $(OBJECTS)Ce Makefile doit être utilisé après avoir appelé le script vsvars.bat s'il est utilisé avec Visual Studio !
Si vous utilisez un make d'origine GNU, vous pouvez utiliser ce Makefile
# Précise le compilateur précis à utiliser
ifdef ON_WINDOWS
export compiler-bindir := "a:/program files/microsoft visual studio 9.0/vc/bin"
endif
export NVCC := a:/cuda/bin/nvcc.exe
%.o : %.cpp
$(NVCC) -c %^ $(CFLAGS) -o $@
$(NVCC) -M %^ $(CFLAGS) > $@.dep
%.o : %.c
$(NVCC) -c %^ $(CFLAGS) -o $@
$(NVCC) -M %^ $(CFLAGS) > $@.dep
%.o : %.cu
$(NVCC) -c %^ $(CFLAGS) -o $@
$(NVCC) -M %^ $(CFLAGS) > $@.dep
include $(wildcard *.dep) /dev/null
all : $(OBJECTS)
$(NVCC) $(OBJECTS) $(LDFLAGS) -o app.exe
clean :
$(RM) $(OBJECTS) *.depVous pouvez aussi utiliser la ligne de commande directement :
nvcc -c cu.cu -o cu.obj
nvcc cu.obj -o app.exeVous pouvez aussi décider que le code CUDA sera exécuté sur le processeur, qui émulera alors un GPU. Il suffit d'ajouter emu=1 à la ligne de commande, comme ceci :
make emu=1