


I. GPGPU▲
Les constructeurs ont décidé de créer des langages qui permettent d'exploiter les possibilités de ces processeurs graphiques. Ils n'ont pas été les seuls.
Par exemple, l'université de Stanford a créé le BrookGPU, le tout premier langage, un dérivé du C, qui permet d'utiliser les API DirectX et OpenGL, ainsi que GLSL ou CG. L'avantage de ces solutions est qu'elles sont utilisables sur tous les GPU qui supportent DirectX et/ou OpenGL, c'est-à-dire la plus grande majorité d'entre eux, et la totalité ces dernières années. Cependant, cette universalité se traduit aussi par un manque de performances par rapport à d'autres bibliothèques plus proches du matériel.
Ainsi, ATI a développé Close to Metal, une bibliothèque très bas niveau. Cette bibliothèque sera suppléée par Stream, mais cette dernière est plus spécifiquement dirigée vers les processeurs FireStream, prévus pour le calcul.
Ensuite vient NVIDIA, avec CUDA, une technologie disponible sur toutes les cartes graphiques grand public depuis la série des GeForce 8000 et sur tous les supercalculateurs Tesla.
II. CUDA▲
Ou Compute Unified Device Architecture.
C'est la réponse de NVIDIA aux demandes sans cesse croissantes de puissance de calcul. Cette bibliothèque, dévoilée en 2007, permet d'employer la puissance de calcul des GPU. Elle n'est que la partie logicielle du tout : il faut encore une carte graphique compatible.
CUDA supporte plusieurs langages : le C, le C + + et le Fortran. Vous pouvez donc utiliser conjointement ces trois langages dans vos fonctions et vos kernels.
Il existe déjà quelques wrapper pour CUDA : PyCUDA, destiné à Python, ainsi que JCublas, JCufft et JCudpp, sans oublier CUDA lui-même, avec jCUDA pour Java, sans oublier CuBLAS.Net, un wrapper de CuBLAS pour le CLR .Net.
CUDA est constitué d'un pilote, déjà intégré aux ForceWare les plus récents ; d'un runtime ; et de quelques bibliothèques. CUDA est aussi un langage, dérivé du C (mais n'apportant que peu de modifications : 9 nouveaux mots-clés, 24 nouveaux types et 62 nouvelles fonctions). Ces extensions nécessitent leur compilateur, lui aussi fourni.
CUDA est prévu pour s'exécuter sur un GPU, mais il est aussi disponible sur CPU, en émulation. Les performances sont alors bien moindres, mais cela peut être utile pour tester ses applications sans GPU compatible.
L'API CUDA est de haut niveau : vous ne vous occupez donc pas du GPU directement. CUDA en est une couche d'abstraction.
Voici, graphiquement représentées, toutes les composantes de CUDA et de son utilisation.
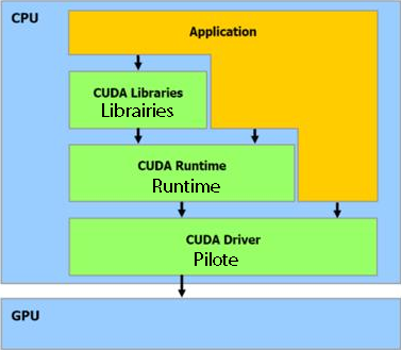
II-A. Pilote▲
- Rôle : transmettre les calculs de l'application au GPU ;
- Distribution avec les ForceWare 178.08 et plus récents ;
- Inconvénient : pas d'automatismes.
II-B. Runtime▲
- Rôle : interface entre le GPU et l'application, en fournissant quelques automatismes ;
- Distribution : en même temps que le pilote ;
- Inconvénient : impossibilité d'optimiser à partir d'un certain point.
II-C. Bibliothèques▲
Pour le moment, CUDA est livré avec CuBLAS et CuFFt, respectivement les implémentations de BLAS (une bibliothèque d'algèbre) et de la transformation rapide de Fourier (utilisée en analyse de Fourier et en traitement du signal). La dernière n'est pas inspirée d'une bibliothèque préexistante.
Ces implémentations reprennent le fonctionnement des bibliothèques originelles (CuBLAS), ou bien des algorithmes les plus performants (CuFFT) et les optimisent au maximum pour CUDA.
III. Un peu de vocabulaire▲
Nous allons continuer cette introduction avec un peu de vocabulaire inhérent à la programmation avec CUDA.
L'hôte est le CPU, c'est lui qui demande au périphérique (le GPU) d'effectuer les calculs.
Un kernel est une portion parallèle de code à exécuter sur le périphérique. Chacune de ses instances s'appelle un thread.
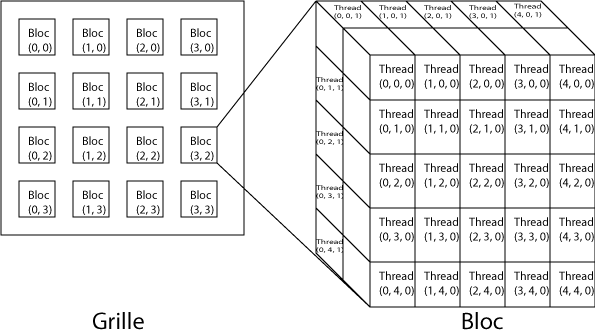
Une grille est constituée de blocs. Chaque bloc est constitué de threads.
Un bloc est un élément des calculs, dissociable d'autres blocs : les blocs ne doivent donc pas être exécutés dans un certain ordre : parallèlement, consécutivement ou toute autre combinaison est possible. C'est pourquoi les threads ne peuvent communiquer qu'avec des threads du même bloc.
Un warp est un ensemble de 32 threads, envoyés ensemble à l'exécution et exécutés simultanément. Quel que soit le GPU utilisé, quelle que soit la quantité de données à traiter, dans n'importe quel cas, un warp sera exécuté sur deux cycles. On peut être sûr et certain qu'ils le seront. Ceci pourra vous aider lors de la conception de vos algorithmes. Par exemple, Mark Harris, chercheur pour NVIDIA dans le rendu graphique en temps réel, fondateur du site GPGPU, utilise cette donnée pour dérouler ses boucles.
Un petit parallèle avec le matériel. Un thread est exécuté par un processeur : posons donc l'égalité entre le thread et le processeur. Ainsi, le bloc est le multiprocesseur, tandis que la grille représente l'entièreté de la carte.
Le calcul hétérogène est l'utilisation des deux types de processeurs disponibles sur nos ordinateurs : les CPU et les GPU. Il s'agit donc d'utiliser le bon type de processeur pour la bonne tâche.
Vous voici prêt pour partir à l'attaque !
IV. CPU et GPU▲
IV-A. Survol de quelques différences▲
La puissance de nos GPU n'a de cesse d'augmenter depuis quelques années. À un point qu'il est désormais possible de les utiliser pour réaliser des calculs autres que pour des jeux. En effet, parmi les CPU, un Intel Pentium 4 cadencé à 3 GHz fournit 4,8 GFlops, un Intel Core 2 Duo E6750 (2,66 GHz), 14,2 GFlops ; chez les GPU, on change de catégorie : la GeForce 9800 GTX, 420 GFlops, pour 675 MHz seulement.
Cependant, ces différences énormes s'expliquent très facilement, explications dans ce tableau.
|
CPU (hors SIMD) |
GPU |
|
|---|---|---|
|
Nombre de tâches |
Une seule et unique |
Le plus grand nombre |
|
Variété des tâches |
Toutes possibles |
Restreinte |
|
Subdivision de la tâche |
Aucune : tout en un coup |
Maximale, pour mieux la répartir sur les différentes unités de calcul |
Il ne faut pas oublier de préciser que les GPU préfèrent travailler avec des vecteurs. Dans le cas contraire, les gains sont réellement minimes.
Les deux types de processeurs travaillent de façon radicalement différente. L'emploi de GPU à la place de CPU ne se fait donc pas en un tour de main : il faut repenser le calcul pour l'adapter au type de processeurs désiré. Si l'on ne change pas sa manière de penser, autant continuer de produire son électricité à la pomme de terre, qui permet quand même de produire assez pour éclairer quelques centimètres ; tandis que la centrale électrique permet d'éclairer des villes entières.
Pour le grand public, les prix se tiennent : un E6750 coûte, actuellement, 140 € ; une 9800 GTX, 150 €. Leurs éditions professionnelles sont légèrement différentes : 1500 $ pour un NVIDIA Tesla S870 plafonnant à 2 Tflops, contre 200 000 $ pour un IBM BlueGene de même puissance. Ici, on remarque bien l'un des grands avantages du GPGPU.
On peut considérer des racks de cartes Tesla comme des supercalculateurs. En effet, ce sont eux qui calculent. Cependant, un ou plusieurs CPU les orchestrent, en plus de leur donner la masse de travail.
Aussi, les GPU ont été, à la base, destinés à et spécialisés pour des calculs intensifs. Ceci leur permet de réserver plus de transistors au traitement des données, au lieu de les utiliser pour le cache ou bien pour la gestion des flux d'entrée ou de sortie.
Ainsi, un GPU doit être constitué de beaucoup de processeurs pour ces calculs : un GPU comporte au strict minimum 32 processeurs (240 pour le T10, 128 en moyenne) et ce, depuis plus qu'un temps certain. Ces processeurs sont les équivalents des cœurs de nos CPU, qui en comportent, en moyenne, deux depuis quelques années et, dans les années à venir, 80. Nous sommes donc bien loin des GPU !
IV-B. Précision des calculs▲
Les GPU actuels, avec CUDA, n'ont qu'une précision FP32, sur 32 bits. Il faut se tourner vers les solutions d'ATI/AMD pour une précision double sur 64 bits, ou bien vers des GPU plus chers, comme les Tesla ou les Quadro, ou bien récents, comme tous les GPU basés sur le GT200 (GeForce GTX260 à GTX295).
Tous les processeurs ne fonctionnent pas à la même précision : sur les premières GeForce compatibles CUDA, tous sont FP32. Sur un T10, huit unités sont FP32 et une seule FP64. Chez AMD, pour huit unités FP64, il y a quatre unités FP32.
Le peu d'unités dédiées au calcul à double précision sur les Tesla et autres explique leur faible puissance à ce niveau de précision, en comparaison de la simple précision ou bien des solutions d'AMD. Ainsi, pour du calcul en haute précision, les solutions NVIDIA tous publics ne sont pas encore au point (AMD ne propose plus de GPGPU pour la même gamme).
Actuellement, tous les processeurs supportent la double précision sur 64 bits.
Plus précisément, NVIDIA met à disposition la liste des écarts avec les standards, ainsi que ses limitations.
- Les additions et soustractions sont souvent associées en une seule instruction ;
- La division et la racine carrée sont implémentées par la réciproque, non conformément aux standards ;
- Pour la multiplication et l'addition, il n'est possible que d'arrondir vers le nombre pair le plus proche ;
- Il n'y a pas de possibilité d'arrondi configurable dynamiquement ;
- Il n'y a pas de signalisation de NaN (Not a Number) ;
- Il n'y a pas de mécanisme de détection d'exception, qui sera masquée selon les standards ;
- Les opérandes de source dénormalisée tendent vers 0 ;
- Le résultat d'une opération avec NaN est un NaN canonique de la forme 0x7fffffff ;
- En accord avec les standards, si un NaN est passé à min() ou à max(), l'autre sera retourné.
IV-C. GPU▲
IV-C-1. Mémoires▲
IV-C-1-a. Mémoire globale▲
CUDA est capable de lire et d'écrire sur la mémoire embarquée dans la carte graphique. Ces opérations portent, respectivement, les doux noms de gathering et de scattering.
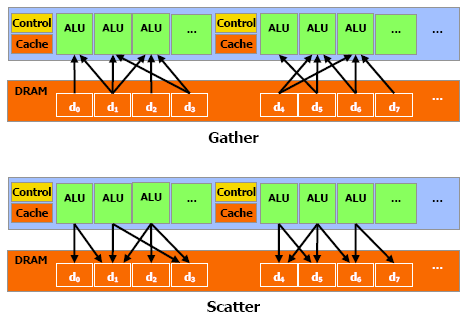
La mémoire globale est la mémoire utilisable de n'importe quel endroit de CUDA, avec les mêmes performances à la clé : cette mémoire n'est pas cachée et il faut attendre 400 à 600 cycles avant d'y accéder. Ce qui laisse un multiprocesseur inactif pendant ce temps.
Pourquoi une telle latence ?
La mémoire globale est, en général (dans tous les cas, jusqu'à présent), de la DRAM.
Cette mémoire est très bon marché : 1,50 $ en septembre 2008, pour les intégrateurs ! Ceci lui permet d'être utilisée comme mémoire principale de nos ordinateurs.
De plus, elle se révèle compacte : on en fait tenir des Go sans problème sur des cartes !
Pourtant, cette mémoire a un problème et il s'agit de la latence. Elle monte sans problème jusqu'à 30 ns, ce qui représente quand même déjà 30 cycles ! Et sans compter les bus entre le multiprocesseur et la mémoire.
Finalement, cette mémoire n'est pas cachée.
IV-C-1-b. Mémoire locale▲
Cette mémoire est, à l'instar de la mémoire globale, non cachée et avec une latence très élevée.
Cette mémoire n'est utilisée que pour certaines variables, qui y sont placées automatiquement. En effet, certains tableaux, normalement placés dans les registres, sont trop grands : il leur faut donc un espace plus grand, qu'offre la mémoire locale.
IV-C-1-c. Mémoire constante▲
La mémoire constante est cachée : la lecture depuis cette mémoire ne coûte qu'un cycle. Pour tous les threads d'un demi-warp, la lecture depuis la mémoire constante est aussi rapide que depuis un registre, aussi longtemps que tous les threads lisent le même emplacement mémoire. Le coût de lecture augmente linéairement avec le nombre d'adresses différentes demandées par les threads. Il est recommandé que tous les threads d'un warp utilisent la même adresse et non seulement ceux de demi-warps, vu que les périphériques futurs le requerront pour un fonctionnement optimal.
Chaque multiprocesseur dispose d'une mémoire réservée aux constantes, d'une taille de 8 ko, dans le cas des GeForce 8800.
IV-C-1-d. Mémoire des textures▲
Cet espace mémoire est caché, le coût de la lecture est donc très faible.
Cette mémoire est optimisée pour un espace à deux dimensions, ainsi, les threads d'un même warp qui lisent à des adresses proches auront des performances optimales.
Aussi, elle est prévue pour des demandes de flux avec une latence constante.
La lecture des mémoires du périphérique par le mécanisme des textures peut être un avantageux substitut à la lecture depuis les mémoires globale ou constante.
Les textures seront approfondies plus tard, mais voici un avant-goût.
Les textures permettent vraiment de simplifier le traitement d'images : elles permettent la mise en œuvre de filtrages bilinéaires et trilinéaires très facilement et l'accès aléatoire aisé aux pixels.
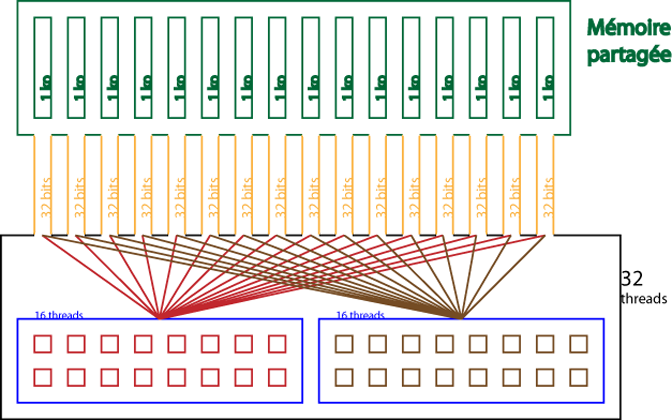
IV-C-1-e. Mémoire partagée▲
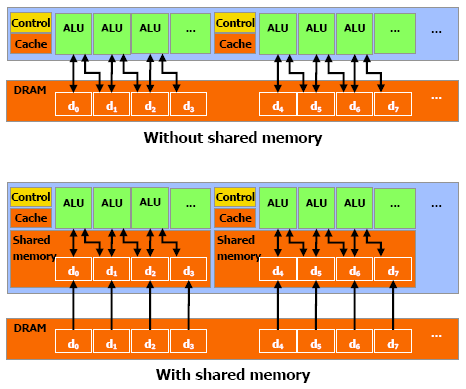
Cette mémoire est présente sur le chipset, ce qui lui permet d'être assez rapide, plus que la mémoire locale.
En fait, pour tous les threads d'un warp, accéder à cette mémoire est aussi rapide que d'accéder à un registre, tant qu'il n'y a pas de conflit entre les threads.
Pour permettre une bande passante assez élevée, la mémoire partagée est divisée en modules de mémoire, les banques, qui peuvent être accédées simultanément. Ainsi, n lectures ou écritures qui tombent dans des banques différentes peuvent être exécutées simultanément dans un warp, ce qui permet d'augmenter sensiblement la bande passante, qui devient n fois plus élevée que celle d'un module.
Cependant, si deux demandes tombent dans la même banque, il y a un conflit de banques et l'accès doit être sérialisé. Le matériel divise ces requêtes problématiques en autant de requêtes que nécessaire pour qu'aucun problème n'ait lieu, ce qui diminue la bande passante d'un facteur équivalent au nombre de requêtes total à effectuer.
Pour des performances maximales, il est donc très important de comprendre comment les adresses mémoires sont reliées aux banques, pour pouvoir prévoir les requêtes et, ainsi, minimiser les conflits.
Dans le cas d'un espace en mémoire partagée, les banques sont organisées pour que des mots successifs de 32 bits soient assignés à des banques successives. Chaque banque a une bande passante de 32 bits tous les deux cycles d'horloge.
Pour le moment, un warp a une taille de 32 threads et il y a 16 banques.
Une requête en mémoire partagée pour un warp est divisée en deux : une partie pour le premier demi-warp, une autre, pour l'autre moitié. Ce qui a pour conséquence qu'il ne peut y avoir de conflit entre chaque demi-warp. Les conflits seront détaillés plus tard.
Actuellement, la mémoire partagée atteint un total de 16 ko, 1 ko pour chaque banque.
Pour résumer ceci, voici un schéma qui reprend l'essentiel des caractéristiques présentées ici.
IV-C-1-f. Registres▲
Généralement, l'accès à un registre ne prend pas un seul cycle supplémentaire par instruction, mais des retards peuvent apparaître, suite aux dépendances de lecture après écriture et des conflits qui peuvent se produire.
Les retards introduits pas les dépendances peuvent être ignorés, dès qu'il y a au moins 192 threads actifs par multiprocesseur, qui permettent de les cacher.
Le compilateur et l'organisateur des threads organisent les instructions pour des performances optimales, qui nécessitent d'éviter les conflits avec les banques. Le meilleur moyen d'obtenir de bonnes performances est d'utiliser un multiple de 64 comme nombre de threads par bloc. Une application n'a strictement aucun moyen de contrôler ces conflits.
Chaque multiprocesseur dispose de 8192 registres.
IV-C-1-g. Mémoire système▲
Depuis les GT200 (GeForce GTX 260 à 295), il est désormais possible d'utiliser la mémoire principale du système, alias RAM, grâce à CUDA 2.2.
Les appels à cette mémoire ne peuvent être fréquents : ils sont encore plus lents que les appels à la mémoire locale (700 à 800 cycles de latence !). Mais la RAM est disponible, de nos jours, en quantités plus grandes que celle disponible sur nos GPU.
IV-C-2. Shaders▲
Les calculs demandés à CUDA sont, pour le moment, effectués sur les unités de shaders, les processeurs les plus rapides sur les GPU. Par exemple, les GeForce 8800 GTX ont des unités cadencées à 1,2 GHz.
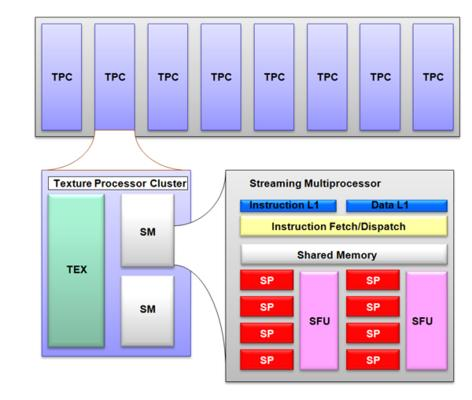
Chaque unité de traitement des shaders est, comme montré ci-dessus, constituée de Texture Processor Clusters (TPC).
Chacun de ces clusters est fait d'une unité de traitement des textures (TEX) et de deux unités de traitement des flux (SM, Streaming Multiprocessor).
Vous n'avez pas vraiment besoin d'en savoir beaucoup plus pour pouvoir aborder CUDA. Cependant, si vous en voulez encore, faites-vous plaisir avec la section suivante !
IV-C-2-a. Plus de précisions▲
Chacun de ces deux processeurs contient une interface qui code et décode les instructions et qui les lance. Derrière l'interface, plusieurs unités exécutent les instructions. Les calculateurs fonctionnent deux fois plus vite que l'interface !
Ces calculateurs sont huit unités de calcul (SP) et deux unités superfonctionnelles (SFU).
À chaque cycle, l'interface choisit un warp prêt à être exécuté.
Pour exécuter toutes les instructions des 32 threads, il faudra quatre cycles. Cependant, vu de l'interface, cela prendra deux cycles.
Pour éviter que l'interface reste inactive pendant un cycle, l'idéal est d'alterner les types de warps : un premier pour les SP, un second pour les SFU.
IV-C-2-b. Limites▲
Un SM étant composé de huit SP, on sera donc limité à l'exécution de huit blocs en simultané. De plus, l'exécution est limitée à 65 536 blocs et 512 threads par bloc au total.
Vous n'avez pas encore eu un aperçu du temps consacré au calcul en fonction des différents paramètres.
En faisant varier le nombre de blocs de calcul sur un même problème, voici les résultats que l'on peut obtenir, avec de simples opérations d'entrée/sortie dans une table. Un bloc correspond à un thread sur un CPU, que l'on peut affecter à un cœur.
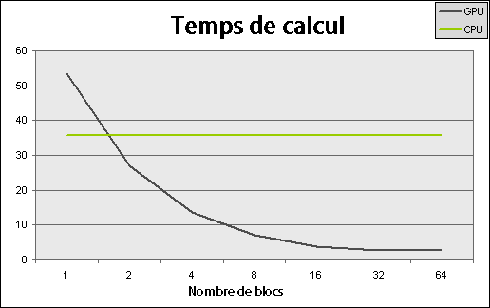
Le processeur utilisé ici est un simple cœur, ses performances en fonction du nombre de threads restent donc stables. S'il s'agissait d'un quad-core, le minimum serait situé à quatre threads.
La carte graphique, une GeForce 8800 GTX, possède seize processeurs, qui ne donnent leur pleine puissance qu'à deux blocs chacun. NVIDIA recommande toutefois d'utiliser au moins une centaine de blocs, afin de pouvoir utiliser la puissance de chipsets plus récents et à venir.
IV-D. CPU▲
Il exécute uniquement les instructions dans l'ordre assigné, sans parallélisation (sauf architectures multicores et multiCPU, qui nécessitent quand même une action à la conception).
Les instructions sont aussi écrites en mémoire, pour exécution. Cependant, les données avec lesquelles il faudra travailler sont souvent dans la même mémoire !
D'habitude, il ne travaille pas directement en mémoire : les données sont copiées dans des registres puis manipulées et enfin stockées en mémoire.
À l'origine, CPU et mémoire partageaient les mêmes fréquences. Mais le premier a accéléré et la seconde ne l'a pas rattrapé : au point que, si les processeurs actuels lisaient directement dans la mémoire, ils ne seraient utilisés que 10 % du temps.
IV-D-1. Mémoire cache▲
C'est pour cela que des caches ont été installés : il s'agit de petites quantités de mémoire, mais très rapide, qui se placent entre le CPU et la mémoire centrale. Ils ne sont utilisés que pour les instructions fréquemment utilisées et les données. Il en existe deux niveaux : L1 et L2, exceptionnellement un troisième, L3, sur les processeurs les plus chers (réservés généralement aux serveurs).
Cependant, ces mémoires très rapides ne sont pas présentes en grandes quantités sur nos CPU, vu leur prix : en moyenne, le mégaoctet de cache coûte 100 fois plus cher que le mégaoctet de RAM ! Le cache fonctionne aussi dix fois plus vite que la RAM, avec un temps d'accès de cinq à dix fois inférieur.
Les caches sont utilisés de manière transparente par le matériel. Ils se font les miroirs des données en mémoire. Ils transportent les données où elles sont nécessaires quand cela est demandé. Ces données ne sont remplacées que quand des données plus urgentes arrivent.
Si les données demandées par le CPU sont disponibles sur le cache, celui-ci les lui envoie, le CPU ne doit pas attendre. Par contre, si elles ne le sont pas, la demande est effectuée en aval, sur des mémoires plus lentes et le CPU doit attendre.
IV-D-2. Pipelines d'instructions▲
Supposons qu'un CPU prenne trois cycles pour une multiplication de paires. Combien de temps prendra-t-il pour multiplier n paires ? Nous pourrions dire 3 n cycles. Il est possible de réduire ce nombre.
La multiplication aura lieu dans une ligne de production. Nous pouvons avoir plus d'une paire de nombres en calcul en même temps. Dans ce cas, les multiplications prendront n + 2 cycles.
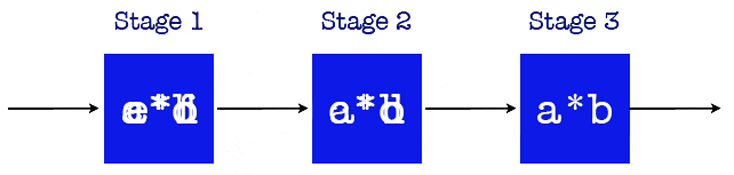
Notre but, pour atteindre cette vitesse, est de garder le pipeline rempli.
Dans une architecture avec pipelines, il est préférable d'avoir le moins possible de branches.
do i=start,end
a(i) = b * c(i)
end dodo i=start,end
if( c(i) == 0 )
a(i) = 0
else if( c(i) == 1 )
a(i) = b
else
a(i) = b * c(i)
end if
end doIV-D-3. Exécution superscalaire▲
Les CPU modernes ont plusieurs unités de calcul, qui peuvent effectuer un nombre limité d'instructions en parallèle.
Le matériel examine les instructions pour repérer des opportunités d'optimisation.
i = i + 1;
j = j + 1;
a = b * c;Les branches limitent ces opportunités et les unités d'exécution sont laissées en attente pendant l'évaluation des conditions.
Les CPU essayent toutes sortes d'autres astuces, comme la prédiction de branches, l'exécution spéculative ou autres, dont le compilateur et le CPU s'occupent.